


爬取亚马逊bestsellers首页的链接
标签: Python爬虫
为了方便构造小类目的链接,你的首先知道大类目的链接,
比如你 知道了大类名称之后,在其的小类目的id直接凭借到其后面就可了

1.代码如下:
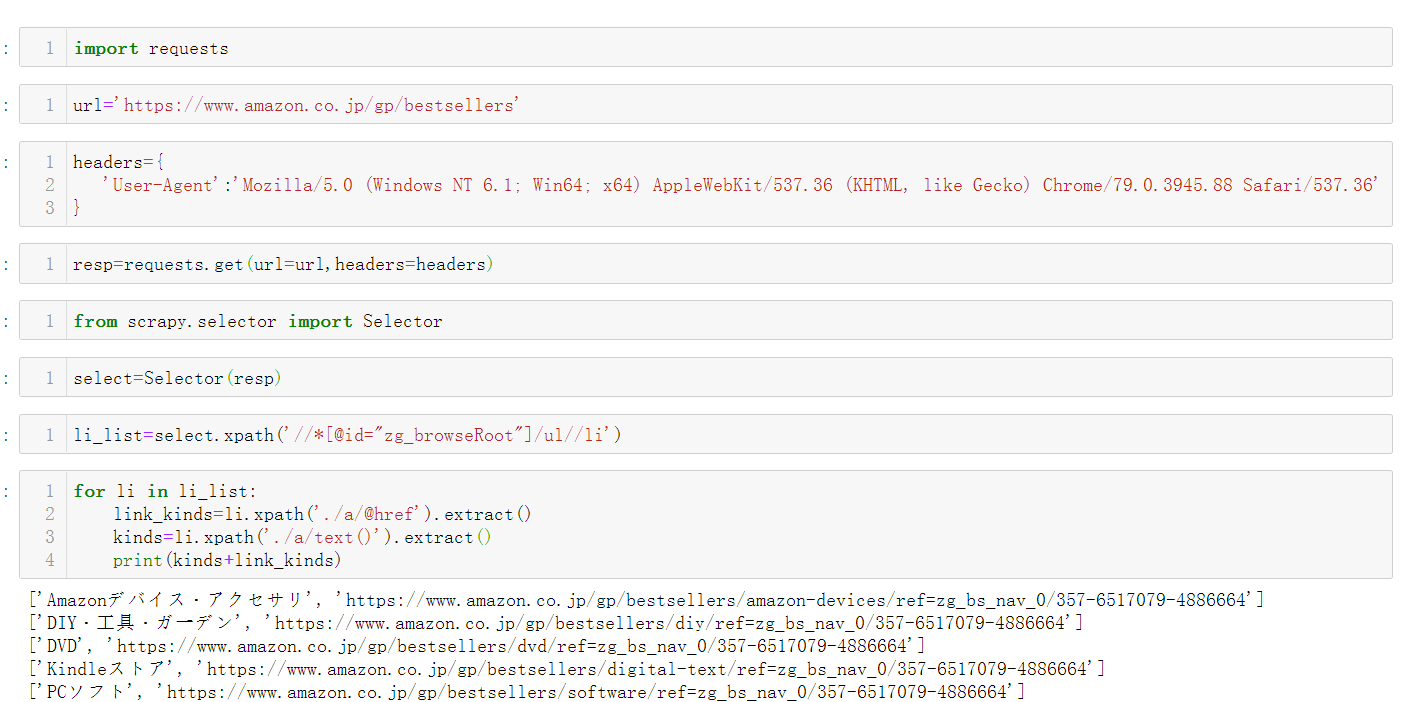
import requests
url='https://www.amazon.co.jp/gp/bestsellers'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
resp=requests.get(url=url,headers=headers)
from scrapy.selector import Selector
select=Selector(resp)
li_list=select.xpath('//*[@id="zg_browseRoot"]/ul//li')
for li in li_list:
link_kinds=li.xpath('./a/@href').extract()
kinds=li.xpath('./a/text()').extract()
print(kinds+link_kinds)
#保存的话,我是保存为csv文件
# 保存csv文件,需要传入一个列表。
import csv
with open("./kinds_link.csv",'a',encoding="utf-8",newline='') as csvfile:
writer = csv.writer(csvfile)
for li in li_list:
link_kinds=li.xpath('./a/@href').extract()
kinds=li.xpath('./a/text()').extract()
print(kinds+link_kinds)
writer.writerow(kinds+link_kinds) #按行写入
2.另外还有一种解析为xpath的包效果一样的,,
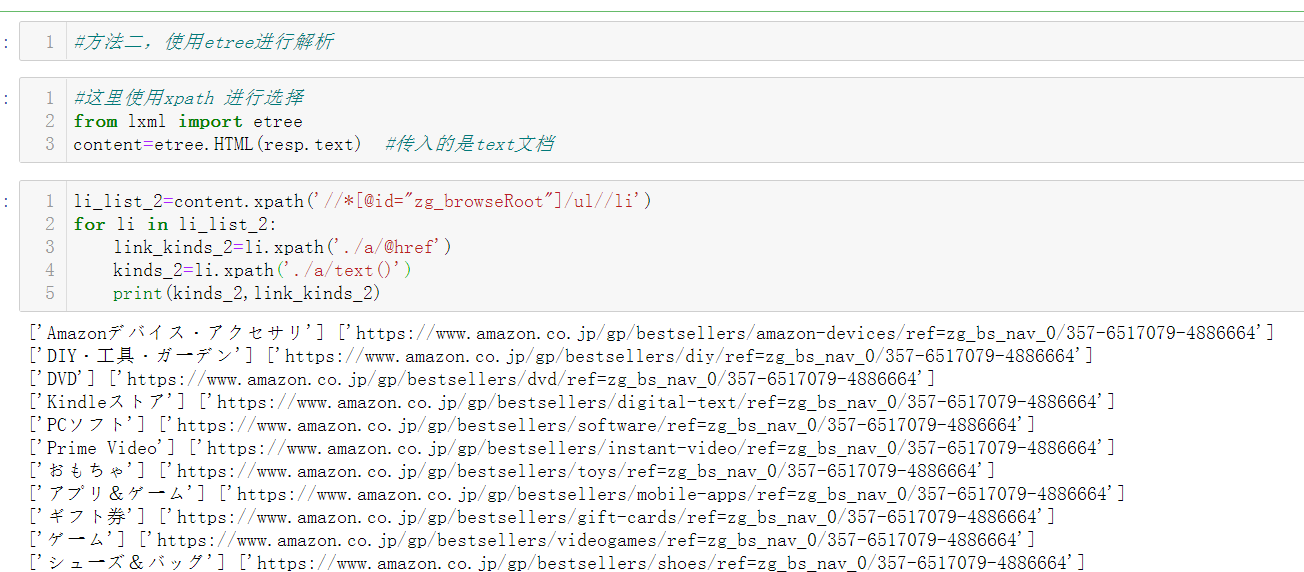
智能推荐

python selenium 爬取亚马逊商品(一)
1、环境 pycharm+selenium+pyquery+xlsxwrite 2、功能说明 爬取亚马逊指定商品 duvet insert的信息,并将获取到的信息通过xlsxwrite写入到excel中 3、完整代码 4、结果 5、缺点 查找的产品已经写死在了代码里,无法自己更换,所以需要一个可以能够读取配置信息,自己添加关键词搜索的功能 ...

【python爬虫自学笔记】-----爬取简书网站首页文章标题与链接
参考:https://blog.csdn.net/csdn2497242041/article/details/77170746...

【Python爬虫】爬取搜狗首页的页面数据
分析 1、指定url 首先进入搜狗搜索页面,指定url,并进行UA伪装。 UA就是User-Agent,UA伪装就是让爬虫对应的请求载体身份标识伪装成某一款浏览器。因为门户网站的服务器会检测对应请求的载体身份标识,如果检测到请求的载体身份标识为某一款浏览器,就说明该请求是一个正常的请求。但是,如果检测到请求的载体身份标识不是基于某一款浏览器的,则表示该请求为不正常的请求(爬虫),服务器就很有可能会...

Python实现爬取亚马逊产品评论
Python实现爬取亚马逊产品评论 一、最近一直在研究爬取亚马逊评论相关的信息,亚马逊的反爬机制还是比较严格的,时不时就封cookie啊封ip啊啥的。而且他们的网页排版相对没有那么规则,所以对我们写爬虫的还是有点困扰的,经过一天的研究现在把成果及心得分享给大家 1.先是我们所需要的库,我们这里是用xpath进行内容匹配,将爬取的内容存入Mysql,所以以下就是我们所需要的库 2.接下来是根据ASI...
猜你喜欢


pyquery+selenium 爬取亚马逊商品信息(一)
需求 需要大量竞品信息做数据分析,爬取亚马逊蓝牙耳机商品、名称、制造商、产品关于、用户评分等信息,商品量约7K,环境anaconda+Pycharm。 设计思路 首先获取亚马逊商城列表每一个商品的URL并,将其存入一个Excel文件。第二个工具读取前面保存的URL,利用pyquery+selenium 获取网页信息。并保存到最终成品——Excel表格中。 环境准备 使用we...


新发的日常小实验——使用IETester测试不同IE版本的浏览器,测试网页JS的兼容性(console未定义兼容测试)
文章目录 一、痛点:IE兼容测试 二、关于IETester 三、IETester下载 四、写个html测试js的console接口 五、测试结果 六、js兼容处理 一、痛点:IE兼容测试 之前使用.Net的Winform桌面应用框架做了一个PC版的迷你浏览器(使用IE内核),方便拉起网页支付。 有用户反馈打开支付页面报了如下的错:“console”未定义 到底是多么老旧的I...

linux下搭建nginx及配置
文章目录 下载nginx 解压nginx资源包 准备编译环境 安装编译 查找安装路径并启动nginx 浏览器访问 下载nginx 下载地址:https://nginx.org/en/download.html 这里用的是nginx-1.16.1版本 解压nginx资源包 准备编译环境 安装编译 查找安装路径并启动nginx 浏览器访问 http://IP...

