


pandas操作04
数据离散化
自动分组
pd.qcut(data,bins) :data是想要分组的数据,bins是分几组
series.value_counts():统计分组次数
自定义分组
pd.cut(data,bins) #bins自己指定分组区间
one-hot编码矩阵
pandas.get_dummies(data, prefix=None)
prefix:分组名字
示例:
import pandas as pd
data=pd.read_csv("./stock_day.csv")
data_p=data['p_change']
p_counts=pd.qcut(data_p,10) #自行分组
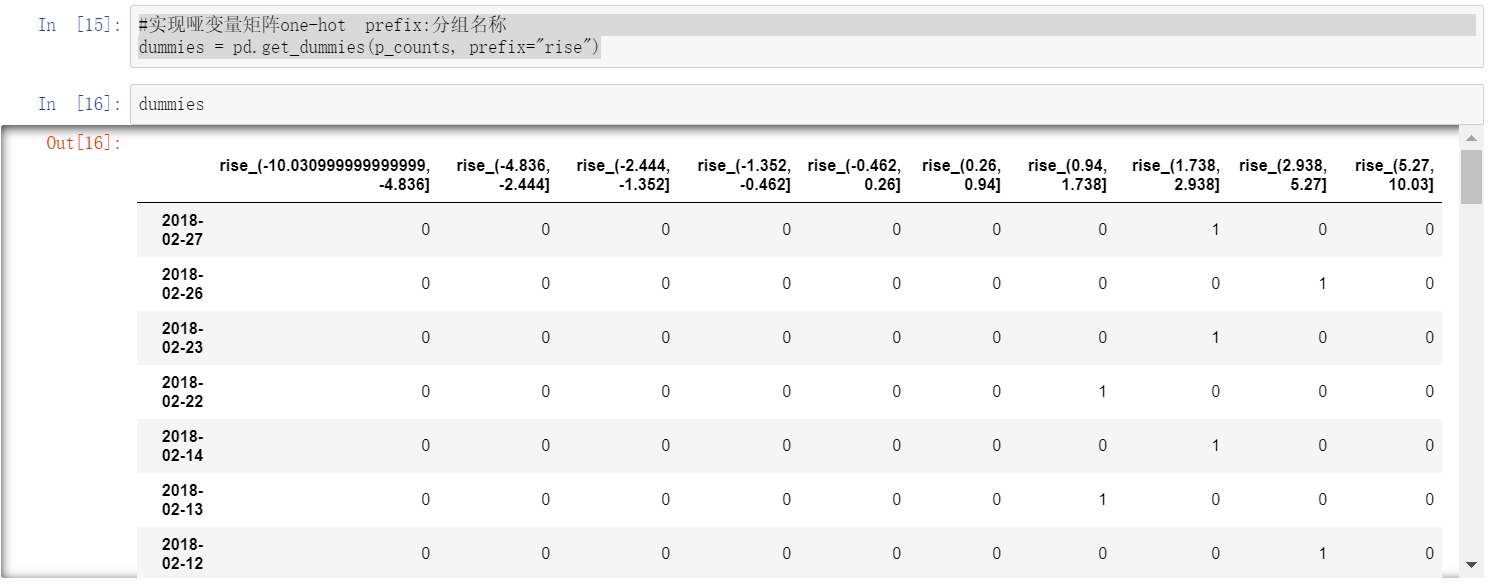
#实现哑变量矩阵one-hot
dummies = pd.get_dummies(p_counts, prefix="rise")
数据合并
pd.concat([data1, data2], axis=1)
按照行或列进行合并,axis=0为列索引,axis=1为行索引
pd.merge(left, right, how='inner', on=None)
left:表1
right:表2
how:按照何种方式合并(inner,outer,left,right)
on:指定的共同键
示例(接上面):
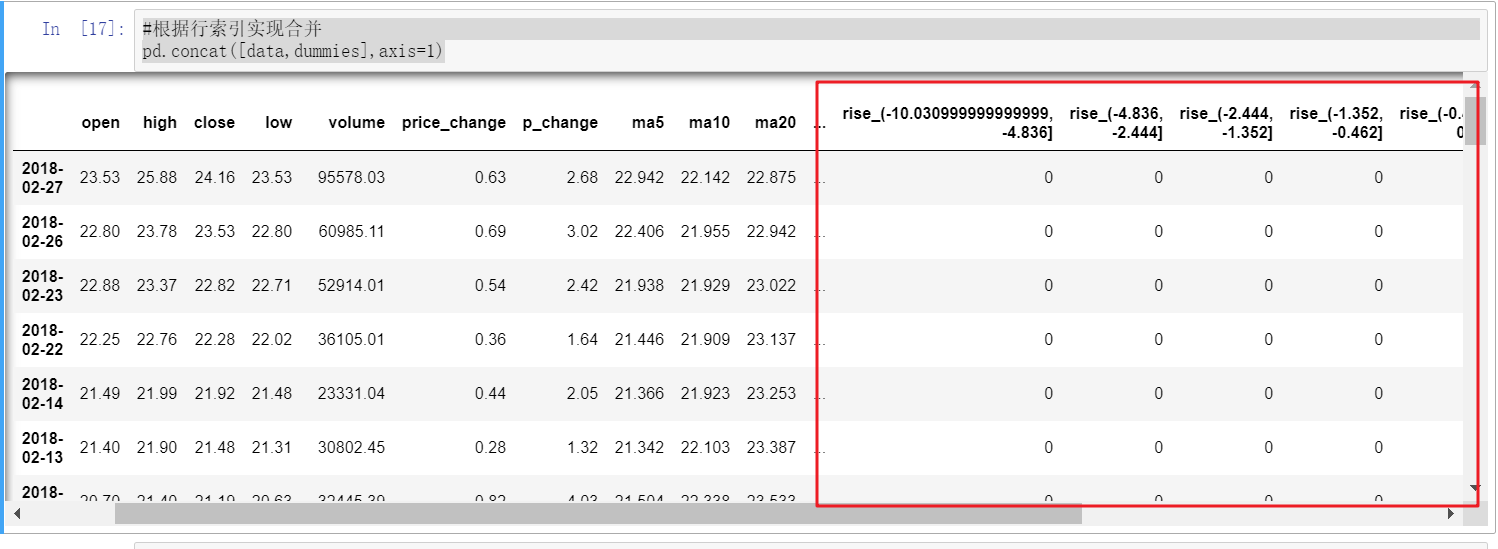
#根据行索引实现合并
pd.concat([data,dummies],axis=1)
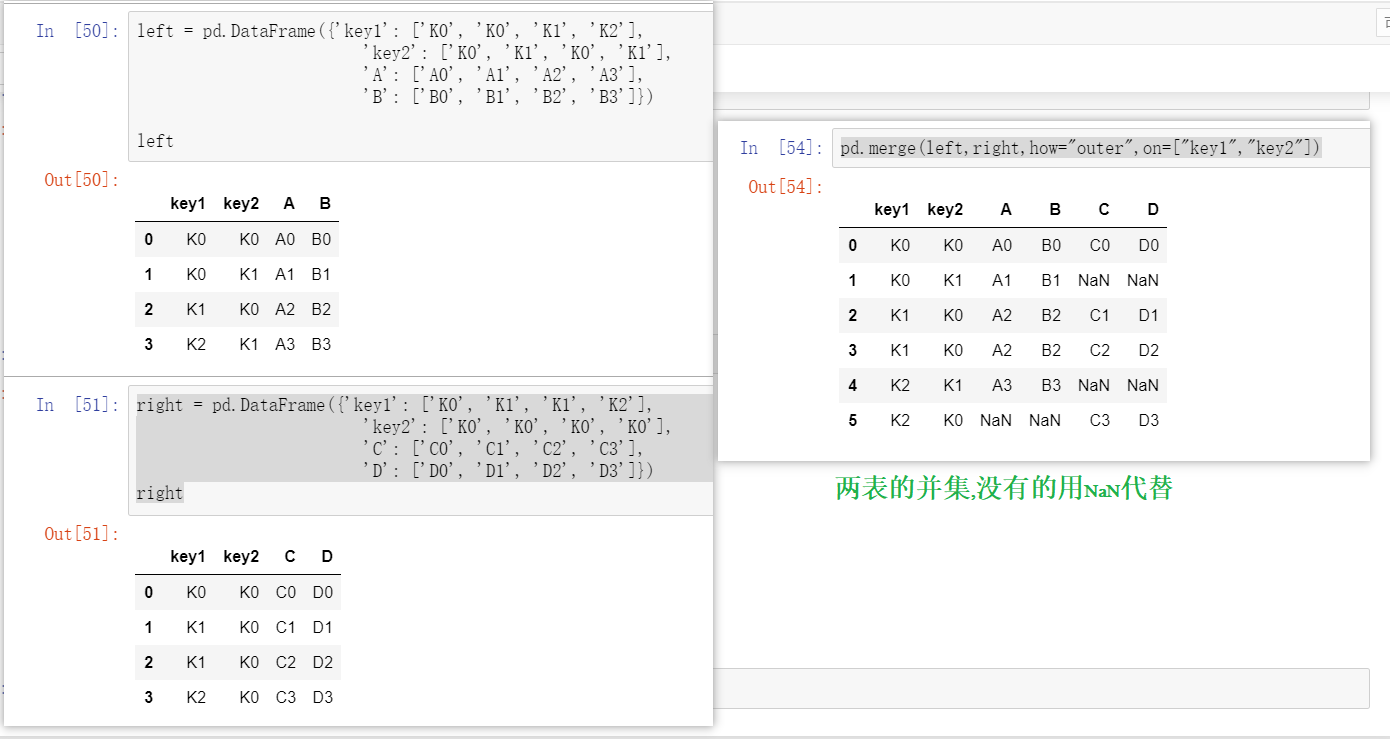
merge示例:
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
#内联
pd.merge(left,right,how="inner",on=["key1","key2"])
#左联
pd.merge(left,right,how="left",on=["key1","key2"])
#右联
pd.merge(left,right,how="right",on=["key1","key2"])
#外联
pd.merge(left,right,how="outer",on=["key1","key2"])

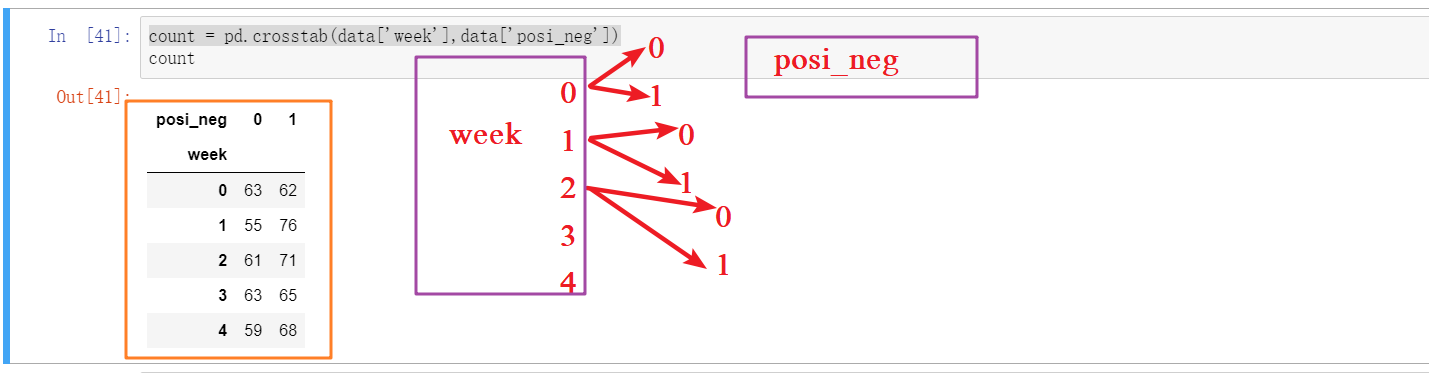
交叉表与透视表
import numpy as np
date=pd.to_datetime(data.index).weekday
data['week']=date #增加一列星期
data['posi_neg']=np.where(data['p_change']>0,1,0)
data['posi_neg'] #增加一列posi_neg
#按照星期进行分组
#按照posi_neg进行分组
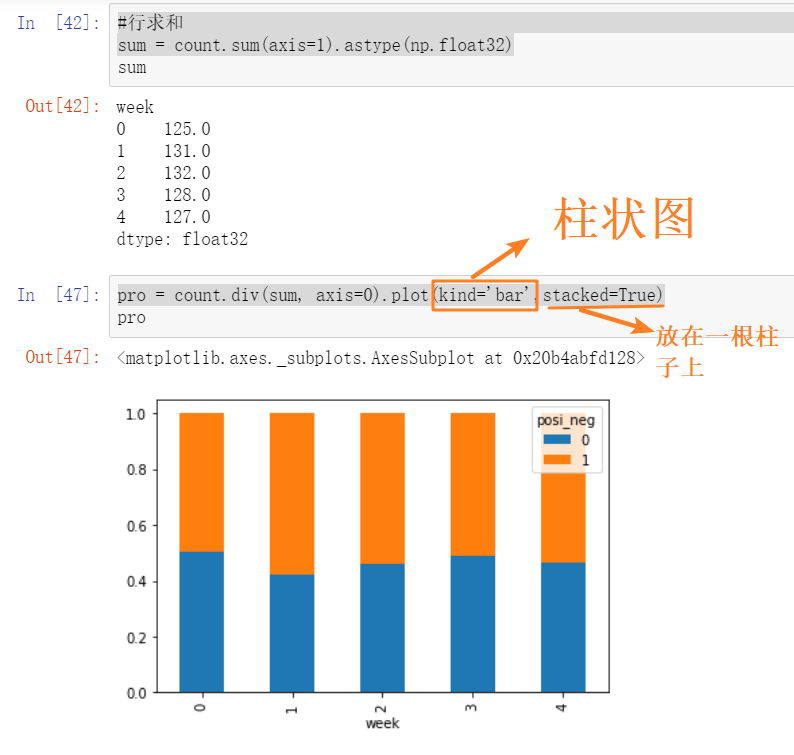
count = pd.crosstab(data['week'],data['posi_neg'])
#行求和
sum = count.sum(axis=1).astype(np.float32)
pro = count.div(sum, axis=0).plot(kind='bar',stacked=True)
智能推荐

pandas常见操作
处理缺失值 分组统计 https://blog.csdn.net/elecjack/article/details/50760736 df[df[‘列名’].isin([相应的值])] 这个命令会输出等于该值的行。 有时,你可能希望得到DataFrame中多个相关列的一张柱状图。例如: 将pandas.value_counts传给该DataFrame的apply函数,就会出...

pandas基础操作
pandas基础操作 对象的创建 对象的访问 时间序列 较为简单的可视化 文件读写 普通文件的读写 python和mysql数据库 pandas基础操作 Pandas是一个强大的时间序列数据处理工具包,最初开发用于分析财经数据,现在广泛的应用于数据分析领域。 对象的创建 pandas的两个基本数据结构分别是Series和DataFrame,其中Series是最基本的数据结构,用来表达一...

Pandas操作02
CSV 打开csv类型的文件 示例: 保存csv格式文件 示例: HDF5(推荐使用) 读取HDF5文件 示例: 如果显示: 则需要安装: 存储文件: 示例: 再次读取的时候, 需要指定键的名字 JSON 读取json文件 示例: 存为json 查找数据 直接使用行列索引查找,但必须是先列后行 根据行列索引找到对应的值 根据行索引下标提取数据 赋值,将某一列全赋值为1 排序 筛选 综合分析,可以直...

Pandas简单操作
pandas读取csv文件 运行环境jupyter read_csv()基本参数:文件路径 Pandas抽取数据 如果数据存在索引,可以通过索引抽取其中一列或者一行 如果需要抽取列中特定的属性,可以在抽取时指定属性为条件。可以直接直接抽取一个属性或多个属性。然后通过pandas的to_csv()方法写到本地文件夹,to_csv()需要参数来指定位置。 或 Pandas日期操作 通过pandas中的...

猜你喜欢
pandas常用操作
1、创建一个空的DataFrame 2、txt、csv、excel、数据库 数据读取 参考文章:Python之Pandas知识点,详细参数讲解可看此文章 3、数据写出。如将数据导入数据库,或导出为excel文件 参考文章:Python之Pandas知识点,详细参数讲解可看此文章。 4、排序 5、计算某列有多少个不同的值,类似sql中distinct 6、分组函数(类似sql中group by) 7...

pandas groupby 分组操作
最一般化的groupby 方法是apply. 新生成一列 根据分组选出最高的5个tip_pct值 对smoker分组并应用该函数 本文转自张昺华-sky博客园博客,原文链接:http://www.cnblogs.com/bonelee/p/7596676.html,如需转载请自行联系原作者...


新发的日常小实验——使用IETester测试不同IE版本的浏览器,测试网页JS的兼容性(console未定义兼容测试)
文章目录 一、痛点:IE兼容测试 二、关于IETester 三、IETester下载 四、写个html测试js的console接口 五、测试结果 六、js兼容处理 一、痛点:IE兼容测试 之前使用.Net的Winform桌面应用框架做了一个PC版的迷你浏览器(使用IE内核),方便拉起网页支付。 有用户反馈打开支付页面报了如下的错:“console”未定义 到底是多么老旧的I...

linux下搭建nginx及配置
文章目录 下载nginx 解压nginx资源包 准备编译环境 安装编译 查找安装路径并启动nginx 浏览器访问 下载nginx 下载地址:https://nginx.org/en/download.html 这里用的是nginx-1.16.1版本 解压nginx资源包 准备编译环境 安装编译 查找安装路径并启动nginx 浏览器访问 http://IP...

