


Python实现KNN算法
一、KNN算法概述
kNN(k Nearest Neighbors)算法又叫 k 最临近方法,总体来说 kNN 算法是相对比较容易理解的算法之一。
首先最简单的KNN算法是找到训练集数据中与测试的数据最临近的样本,则这个样本的类型就是测试数据的预测类型。当然KNN算法也可以假设每一个类包含多个样本数据,而且每个数据都有一个唯一的类标记表示这些样本是属于哪一个分类, kNN 就是计算每个样本数据到待分类数据的距离,取和待分类数据最近的k 各样本数据,那么这个k 个样本数据中哪个类别的样本数据占多数,则待分类数据就属于该类别。该算法的基本思路是:在给定测试目标后,考虑在训练文本集中与该目标距离最近(最相似)的 K 个样本,根据这 K 个样本所属的类别判定测试目标所属的类别。
二、算法实现
首先预先给定一个数据集作为训练集数据,训练集数据中的每一组数据都对应一种类型,本鸢尾花题目中,我们只给出了10组训练集数据(可以根据需要更改),所对应类型为’setosa’,‘setosa’,‘setosa’,‘setosa’,‘versicolor’,‘versicolor’,‘versicolor’,‘versicolor’,‘virginica’,‘virginica’。我们在程序中提供了两种算法,一种是找到与测试目标最临近的一个样本,然后以此样本的类型作为测试目标的类型;另外一种是找到与测试目标临近的K个样本,这些样本中出现的类型最多的即是测试目标的类型。
采用欧氏距离的算法作为计算样本与测试目标距离的算法,算法公式如下所示:
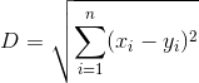
三、代码实现
import math
# 训练集数据(花瓣的长度,花瓣的宽度,花萼的长度,花萼的宽度)
train_list=[[5.1,3.5,1.4,0.2],
[4.9,3.0,1.4,0.2],
[4.7,3.2,1.3,0.2],
[4.6,3.1,1.5,0.2],
[5.0,3.6,1.4,0.3],
[2.9,2.8,1.9,0.3],
[3.6,2.7,2.0,0.3],
[3.9,2.4,0.9,0.3],
[2.5,4.1,1.1,0.1],
[2.7,4.0,0.9,0.1]]
# 训练集数据对应的鸢尾花类型(一共三种类型花)
target_list=['setosa','setosa','setosa','setosa','versicolor','versicolor','versicolor','versicolor','virginica','virginica']
huabanchangdu=float(input("请输入测试花的花瓣长度:"))
huabankuandu=float(input("请输入测试花的花瓣宽度:"))
huaechangdu=float(input("请输入测试花的花萼长度:"))
huaekuandu=float(input("请输入测试花的花萼宽度:"))
def knn(list1,list2,s0,s1,s2,s3):
for i in range(len(list1)):
d=(list1[i][0]-s0)**2+(list1[i][1]-s1)**2+(list1[i][2]-s2)**2+(list1[i][3]-s3)**2
print("第"+str(i)+"组训练集数据与测试花数据的欧氏距离为"+str(math.sqrt(d)))
if i==0:
min=d
minbiaoji=i
if d<min:
min=d
minbiaoji=i
print("该测试花的数据距离第"+str(minbiaoji)+"组数据最近,所以该鸢尾花的类型是:"+list2[minbiaoji])
def Knn(list1,list2,s0,s1,s2,s3):
k=int(input("请输入一个整数值K作为选取临近数据的个数"))
list=[]
for i in range(len(list1)):
d=(list1[i][0]-s0)**2+(list1[i][1]-s1)**2+(list1[i][2]-s2)**2+(list1[i][3]-s3)**2
print("第"+str(i)+"组训练集数据与测试花数据的欧氏距离为"+str(math.sqrt(d)))
list.append([str(math.sqrt(d)),list2[i]])
for l in range(len(list)-1):
for t in range(len(list)-1):
if list[t][0]>list[t+1][0]:
temp=list[t]
list[t]=list[t+1]
list[t+1]=temp
print("训练集数据中与测试花数据临近的K个数据为")
for l in range(k):
print(list[l])
numlist=[]
for l in range(k):
n=0
for i in range(k):
if list[i][1]==list[l][1]:
n=n+1
if l==0:
max=n
maxbiaoji=l
if n>max:
max=n
maxbiaoji=l
print("该测试花的数据距离训练集数据"+str(k)+"个临近中出现次数最多的是:"+list[maxbiaoji][1]+",所以该鸢尾花的类型是:"+list[maxbiaoji][1])
select=input("请选择采用的算法:输入1代表采用一个最临近;输入2代表采用K个临近")
if select==1:
knn(train_list,target_list,huabanchangdu,huabankuandu,huaechangdu,huaekuandu)
else:
Knn(train_list,target_list,huabanchangdu,huabankuandu,huaechangdu,huaekuandu)
四、运行结果
最临近结果(K=1):

出现类型次数最多的结果(K=5)

五、总结
在本次实验作业中,用Python编写实现机器学习导论中的KNN算法代码,期间遇到了一些问题,比如说对列表的操作出现了小失误,导致使用二维列表时出现索引溢出,以及敲代码时出现失误,变量名弄错将非列表变量当做列表变量使用出现TypeError: ‘int’ object is not subscriptable类型错误,还有使用Python中的变量不显式声明类型,对于一些函数返回的类型有一些混淆导致出现很多次,就像TypeError:unsupported operand type(s) for -:’list’ and ‘list’类型错误,还有各种细节错误,经过耐心的查找得到改正。
经过本次实验作业,使我对Python代码更加熟悉,对我Python学习有很大的帮助,提高了对Python的理解。在今后的学习中更加认真,不断学习,不断优秀。
智能推荐
Python: KNN算法的实现
1、KNN介绍 K最近邻(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法。 机器学习,算法本身不是最难的,最难的是: 1、数学建模:把业务中的特性抽象成向量的过程; 2、选取适合模型的数据样本。 这两个事都不是简单的事。算法反而是比较简单的事。 本质上,KNN算法就是用距离来衡量样本之间的相似度。 2、算法图示 ◊ 从训练集中找到和新数据最接近的k条...

Python 实现 KNN 分类算法
文章目录 1. KNN 1.1 KNN 分类算法步骤 1.2 KNN 的优缺点 2. python 实现 本文将详细讲述 KNN 算法及其 python 实现 1. KNN KNN(K-Nearest Neighbour)即 K最近邻,是分类算法中最简单的算法之一。KNN 算法的核心思想是 如果一个样本在特征空间中的 k 个最相邻的样本中的大多数属于某一个类别,则将该样本归为该类别 1.1 KNN...

用Python实现KNN算法
用Python实现KNN算法 最近在玩imbalance的时候,看到imbalanced-learn中牵扯到了KNN算法,所以,就把KNN仔细地研究了一下。首先,KNN算法原理比较简单,通俗易懂。当然,在实现算法的过程中,参考了sklearn的代码风格,这里不得不说,sklearn真是简约大方,实用方便。 k-近邻算法(k-Nearest Neighbour algorithm),又称为KNN算法...

python实现knn分类算法
本文非原创,原博主地址 目的 原生python实现knn分类算法(使用鸢尾花数据集) KNN算法核心思想就是,要确定测试样本属于哪一类,就寻找所有训练样本中与该测试样本“距离”最近的前K个样本,然后看这K个样本大部分属于哪一类,那么就认为这个测试样本也属于哪一类。简单的说就是让最相似的K个样本来投票决定。因此,实现 K 近邻算法时,主要考虑的问题是如何对训练数据进行快速 K...

原生Python实现knn算法
目录 一、题目名称 二、题目内容 三、算法分析 四、调试截图 五、运行结果 六、问题及解决 七、源代码 八、参考文献 一、题目名称 实现knn分类算法 二、题目内容 原生Python实现knn分类算法,并使用鸢尾花数据集进行测试 三、算法分析 knn算法是最简单的机器学习算法之一,通过测量不同特征值之间的距离进行分类。其基本思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最...
猜你喜欢

原生python实现knn算法
作者:无* 时间:2019-10-11 一.题目分析: 原生python实现knn分类算法: 最近邻(k-Nearest Neighbor,KNN)的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本...
python实现KNN(最近邻)算法
KNN(近邻)算法 KNN算法可能是标准数据挖掘算法中最为直观的一种。为了对新个体进行分类,它查找训练集,找到与新个体最相似的那些个体,看看这些个体大多属于哪个类别,就把新个体分到哪个类别 KNN算法几乎可以对任何数据集进行分类,但是,要计算数据集中每两个个体之间的距离,计算量很大 数据集选取 本次数据集选用电离数据,该数据集每行有35个值,前34个为天线采集的数据,最后一个值不是“g...


新发的日常小实验——使用IETester测试不同IE版本的浏览器,测试网页JS的兼容性(console未定义兼容测试)
文章目录 一、痛点:IE兼容测试 二、关于IETester 三、IETester下载 四、写个html测试js的console接口 五、测试结果 六、js兼容处理 一、痛点:IE兼容测试 之前使用.Net的Winform桌面应用框架做了一个PC版的迷你浏览器(使用IE内核),方便拉起网页支付。 有用户反馈打开支付页面报了如下的错:“console”未定义 到底是多么老旧的I...

linux下搭建nginx及配置
文章目录 下载nginx 解压nginx资源包 准备编译环境 安装编译 查找安装路径并启动nginx 浏览器访问 下载nginx 下载地址:https://nginx.org/en/download.html 这里用的是nginx-1.16.1版本 解压nginx资源包 准备编译环境 安装编译 查找安装路径并启动nginx 浏览器访问 http://IP...

