


MySQLЛљДЁЃЈЦпЃЉЃКЫїв§МђНщ
БъЧЉЃК # Ъ§ОнПт(MySQL) Ыїв§
вЛЁЂЫїв§ЪЧЪВУДЃПгХЕуЁЂШБЕу
1ЁЂЫїв§ЕФЙйЗНЖЈвх
MySQLЙйЗНЖдЫїв§ЕФЖЈвхЮЊЃКЫїв§ЃЈIndexЃЉЪЧАяжњMySQLИпаЇЛёШЁЪ§ОнЕФЪ§ОнНсЙЙЁЃ ПЩвдЕУЕНЫїв§ЕФБОжЪЃКЫїв§ЪЧЪ§ОнНсЙЙЁЃ
ФуПЩвдМђЕЅРэНтЮЊЁАХХКУађЕФПьЫйВщевЪ§ОнНсЙЙЁБЁЃ
2ЁЂЫїв§ЕФгХЕугыШБЕу
# гХЕу
1. РрЫЦДѓбЇЭМЪщЙнНЈЪщФПЫїв§ЃЌЬсИпЪ§ОнМьЫїЕФаЇТЪЃЌНЕЕЭЪ§ОнПтЕФIOГЩБО
2. ЭЈЙ§Ыїв§СаЖдЪ§ОнНјааХХађЃЌНЕЕЭЪ§ОнХХађЕФГЩБОЃЌНЕЕЭСЫCPUЕФЯћКФ
# ШБЕу
ЪЕМЪЩЯЫїв§вВЪЧвЛеХБэЃЌИУБэБЃДцСЫжїМќгыЫїв§зжЖЮЃЌВЂжИЯђЪЕЬхБэЕФМЧТМЃЌЫљвдЫїв§СавВЪЧвЊеМгУПеМфЕФ
ЫфШЛЫїв§ДѓДѓЬсИпСЫВщбЏЫйЖШЃЌЭЌЪБШДЛсНЕЕЭИќаТБэЕФЫйЖШЃЌШчЖдБэНјааINSERTЁЂUPDATEКЭDELETEЁЃ
# вђЮЊИќаТБэЪБЃЌMySQLВЛНівЊБЃДцЪ§ОнЃЌЛЙвЊБЃДцвЛЯТЫїв§ЮФМўУПДЮИќаТЬэМгСЫЫїв§СаЕФзжЖЮЃЌ ЖМЛсЕїећвђЮЊИќаТЫљДјРДЕФМќжЕБфЛЏКѓЕФЫїв§аХЯЂ
Ыїв§жЛЪЧЬсИпаЇТЪЕФвЛИівђЫиЃЌШчЙћФуЕФMySQLгаДѓЪ§ОнСПЕФБэЃЌОЭашвЊЛЈЪБМфбаОПНЈСЂзюгХауЕФЫїв§ЃЌЛђгХЛЏВщбЏгяОф
ЖўЁЂmysqlЫїв§НсЙЙ
дФЖСжЎЧАНЈвщПДПДДХХЬПщЫїв§ЯъНтЃКhttps://blog.csdn.net/weixin_44571270/article/details/105899656
1ЁЂBTreeЫїв§
дРэЭМ

УПИіНкЕуЖМДцДЂkeyКЭdataЃЌЫљгаНкЕузщГЩетПУЪїЃЌВЂЧввЖзгНкЕужИеыЮЊnullЃЌжЛгаЪїжІНкЕуЁЂИљНсЕуВХгажИеыЁЃ
2ЁЂB+TreeЫїв§
жЛгавЖзгНкЕуДцДЂdataЃЌвЖзгНкЕуАќКЌСЫетПУЪїЕФЫљгаМќжЕЃЌвЖзгНкЕуВЛДцДЂжИеыЁЃB+ЪїЩЯдіМгСЫЫГађЗУЮЪжИеыЃЌвВОЭЪЧУПИівЖзгНкЕудіМгвЛИіжИЯђЯрСквЖзгНкЕуЕФжИеыЃЌетбљвЛПУЪїГЩСЫЪ§ОнПтЯЕЭГЪЕЯжЫїв§ЕФЪзбЁЪ§ОнНсЙЙЁЃ 
зюжївЊЕФдвђЪЧетПУЪїАЋХжЃЌКЧКЧЁЃвЛАуРДЫЕЃЌЫїв§КмДѓЃЌЭљЭљвдЫїв§ЮФМўЕФаЮЪНДцДЂЕФДХХЬЩЯЃЌЫїв§ВщевЪБВњЩњДХХЬI/OЯћКФЃЌЯрЖдгкФкДцДцШЁЃЌI/OДцШЁЕФЯћКФвЊИпМИИіЪ§СПМЖЃЌЫљвдЦРМлвЛИіЪ§ОнНсЙЙзїЮЊЫїв§ЕФгХСгзюживЊЕФжИБъОЭЪЧдкВщевЙ§ГЬжаДХХЬI/OВйзїДЮЪ§ЕФЪБМфИДдгЖШЁЃЪїИпЖШдНаЁЃЌI/OДЮЪ§дНЩйЁЃ
# ЮЊЪВУДB+ЪїГЩЮЊЪ§ОнПтЯЕЭГЪЕЯжЫїв§ЕФЪзбЁЪ§ОнНсЙЙ
1. ФЧЮЊЪВУДЪЧB+ЪїЖјВЛЪЧBЪїФиЃЌвђЮЊЫќИљНкЕугыЪїжІНкЕуВЛДцДЂdata
2. етбљвЛИіНкЕуОЭПЩвдДцДЂИќЖрЕФkeyЁЃетбљећИіЪїЯрБШBЪїЛсИќМгАЋХжЃЌI/OДЮЪ§ИќЩйЃЁ
3. MyISAMДцДЂв§ЧцВЩгУb-ЪїЪЕЯжЫїв§ЃЌinnodbВЩгУb+ЪїЪЕЯжЫїв§ЃЌвђДЫетвВЪЧinnodbгУЕФИќМгЖрЕФдвђжЎвЛ
3ЁЂB+ЪїгыB-ЪїЕФЧјБ№
# B+ЪїгыB-ЪїЕФЧјБ№
1. ДгДцДЂЪ§ОнРДПД
b-ЪїЃЌвЖзгНкЕуИњЗЧвЖзгНкЕуЖМДЂДцЪ§Он
b+ЪїЃЌжЛгадквЖзгНкЕуДЂДцЪ§Он
2. ДгНсЙЙЩЯРДПД
BЪїЃКгаађЪ§зщ+ЦНКтЖрВцЪїЃЛ
B+ЪїЃКгаађЪ§зщСДБэ+ЦНКтЖрВцЪїЃЛ
# B+ЪїЕФЬиЕуЃК
1ЁЂB+ЪїЕФВуМЖИќЩйЃКЯрНЯгкBЪїB+УПИіЗЧвЖзгНкЕуДцДЂЕФЙиМќзжЪ§ИќЖрЃЌЪїЕФВуМЖИќЩйЫљвдВщбЏЪ§ОнИќПьЃЛ
2ЁЂB+ЪїВщбЏЫйЖШИќЮШЖЈЃКB+ЫљгаЙиМќзжЪ§ОнЕижЗЖМДцдквЖзгНкЕуЩЯЃЌЫљвдУПДЮВщевЕФДЮЪ§ЖМЯрЭЌЫљвдВщбЏЫйЖШвЊБШBЪїИќЮШЖЈ;
3ЁЂB+ЪїЬьШЛОпБИХХађЙІФмЃКB+ЪїЫљгаЕФвЖзгНкЕуЪ§ОнЙЙГЩСЫвЛИігаађСДБэЃЌдкВщбЏДѓаЁЧјМфЕФЪ§ОнЪБКђИќЗНБуЃЌЪ§ОнНєУмадКмИпЃЌЛКДцЕФУќжаТЪвВЛсБШBЪїИпЁЃ
4ЁЂB+ЪїШЋНкЕуБщРњИќПьЃКB+ЪїБщРњећПУЪїжЛашвЊБщРњЫљгаЕФвЖзгНкЕуМДПЩЃЌЃЌЖјВЛашвЊЯёBЪївЛбљашвЊЖдУПвЛВуНјааБщРњЃЌетгаРћгкЪ§ОнПтзіШЋБэЩЈУшЁЃ
# BЪїЯрЖдгкB+ЪїЕФгХЕу
ШчЙћОГЃЗУЮЪЕФЪ§ОнРыИљНкЕуКмНќЃЌЖјBЪїЕФЗЧвЖзгНкЕуБОЩэДцгаЙиМќзжЦфЪ§ОнЕФЕижЗЃЌЫљвдетжжЪ§ОнМьЫїЕФЪБКђЛсвЊБШB+ЪїПьЁЃ
4ЁЂОлДиЫїв§гыЗЧОлДиЫїв§
вВНаОлМЏЫїв§гыЗЧОлМЏЫїв§
- MyISAM
dataДцЕФЪЧЪ§ОнЕижЗЁЃЫїв§ЪЧЫїв§ЃЌЪ§ОнЪЧЪ§ОнЁЃЫїв§ЗХдкXX.MYIЮФМўжаЃЌЪ§ОнЗХдкXX.MYDЮФМўжаЃЌЫљвдвВНаЗЧОлМЏЫїв§ЁЃ
- InnoDB
dataДцЕФЪЧЪ§ОнБОЩэЁЃЫїв§вВЪЧЪ§ОнЁЃЪ§ОнКЭЫїв§ДцдквЛИіXX.IDBЮФМўжаЃЌЫљвдвВНаОлМЏЫїв§ЁЃ
MyISAM гыInnoDBНЈБэЮФМўЖдБШЃКhttps://blog.csdn.net/weixin_44571270/article/details/106710860
1. ОлДиЫїв§ЕФКУДІЃК
? АДееОлДиЫїв§ХХСаЫГађЃЌВщбЏЯдЪОвЛЖЈЗЖЮЇЪ§ОнЕФЪБКђЃЌгЩгкЪ§ОнЖМЪЧНєУмЯрСЌЃЌЪ§ОнПтВЛгУДгЖрИіЪ§ОнПщжаЬсШЁЪ§ОнЃЌЫљвдНкЪЁСЫДѓСПЕФioВйзїЁЃ
2. ОлДиЫїв§ЕФЯожЦЃК
? ЖдгкmysqlЪ§ОнПтФПЧАжЛгаinnodbЪ§Онв§ЧцжЇГжОлДиЫїв§ЃЌЖјMyisamВЂВЛжЇГжОлДиЫїв§ЁЃ
? гЩгкЪ§ОнЮяРэДцДЂХХађЗНЪНжЛФмгавЛжж ЃЌЫљвдУПИіMysqlЕФБэжЛФмгавЛИіОлДиЫїв§ЁЃвЛАуЧщПіЯТОЭЪЧИУБэЕФжїМќ ЁЃ
? ЮЊСЫГфЗжРћгУОлДиЫїв§ЕФОлДиЕФЬиадЃЌЫљвдinnodbБэЕФжїМќСаОЁСПбЁгУгаађЕФЫГађidЃЌЖјВЛНЈвщгУЮоађЕФidЃЌБШШчuuidетжжЁЃЃЈВЮПМОлДиЫїв§ЕФКУДІЁЃЃЉ
етРяЫЕУїСЫжїМќЫїв§ЮЊКЮВЩгУзддіЕФЗНЪНЃК1ЁЂвЕЮёашЧѓЃЌгаађЁЃ2ЁЂФмЪЙгУЕНОлДиЫїв§
5ЁЂfull-textШЋЮФЫїв§
ШЋЮФЫїв§ЃЈвВГЦШЋЮФМьЫїЃЉЪЧФПЧАЫбЫїв§ЧцЪЙгУЕФвЛжжЙиМќММЪѕЁЃЫќФмЙЛРћгУЁОЗжДЪММЪѕЁПЕШЖржжЫуЗЈжЧФмЗжЮіГіЮФБОЮФзжжаЙиМќДЪЕФЦЕТЪКЭживЊадЃЌШЛКѓАДеевЛЖЈЕФЫуЗЈЙцдђжЧФмЕиЩИбЁГіЮвУЧЯывЊЕФЫбЫїНсЙћЁЃ
CREATE TABLE `article` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(200) DEFAULT NULL,
`content` text,
PRIMARY KEY (`id`),
FULLTEXT KEY `title` (`title`,`content`) # ШЋЮФЫїв§
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
ЯожЦЃК
mysql5.6.4вдЧАжЛгаMyisamжЇГжЃЌ5.6.4АцБОвдКѓinnodbВХжЇГжЃЌЕЋЪЧЙйЗНАцБОВЛжЇГжжаЮФЗжДЪЃЌашвЊЕкШ§ЗНЗжДЪВхМўЁЃ
5.7вдКѓЙйЗНжЇГжжаЮФЗжДЪЁЃ
ЫцзХДѓЪ§ОнЪБДњЕФЕНРДЃЌЙиЯЕаЭЪ§ОнПтгІЖдШЋЮФЫїв§ЕФашЧѓвбСІВЛДгаФЃЌж№НЅБЛ solr,elasticSearchЕШзЈУХЕФЫбЫїв§ЧцЫљЬцДњЁЃ
6ЁЂHashЫїв§
HashЫїв§жЛгаMemory, NDBСНжжв§ЧцжЇГжЃЌMemoryв§ЧцФЌШЯжЇГжHashЫїв§ЃЌШчЙћЖрИіhashжЕЯрЭЌЃЌГіЯжЙўЯЃХізВЃЌФЧУДЫїв§вдСДБэЗНЪНДцДЂЁЃ
NoSqlВЩгУДЫжжЫїв§НсЙЙЁЃ
7ЁЂR-TreeЫїв§
R-TreeдкmysqlКмЩйЪЙгУЃЌНіжЇГжgeometryЪ§ОнРраЭЃЌжЇГжИУРраЭЕФДцДЂв§ЧцжЛгаmyisamЁЂbdbЁЂinnodbЁЂndbЁЂarchiveМИжжЁЃ
ЯрЖдгкb-treeЃЌr-treeЕФгХЪЦдкгкЗЖЮЇВщевЁЃ
Ш§ЁЂmysqlЫїв§ЗжРр
1ЁЂжїМќЫїв§
ЩшЖЈЮЊжїМќКѓЪ§ОнПтЛсздЖЏНЈСЂЫїв§ЃЌinnodbЮЊОлДиЫїв§
// ЫцБэвЛЦ№НЈЫїв§ЃК
CREATE TABLE customer (id INT(10) UNSIGNED AUTO_INCREMENT ,customer_no VARCHAR(200),customer_name VARCHAR(200),
PRIMARY KEY(id)
);
unsigned (ЮоЗћКХЕФ)
ЪЙгУ AUTO_INCREMENT ЙиМќзжЕФСаБиаыгаЫїв§(жЛвЊгаЫїв§ОЭаа)ЁЃ
CREATE TABLE customer2 (id INT(10) UNSIGNED ,customer_no VARCHAR(200),customer_name VARCHAR(200),
PRIMARY KEY(id)
);
// ЕЅЖРНЈжїМќЫїв§ЃК
ALTER TABLE customer
add PRIMARY KEY customer(customer_no);
// ЩОГ§жїМќЫїв§ЃК
ALTER TABLE customer
drop PRIMARY KEY ;
// аоИФжїМќЫїв§ЃК
БиаыЯШЩОГ§Еє(drop)дЫїв§ЃЌдйаТНЈ(add)Ыїв§
2ЁЂЕЅжЕЫїв§
МДвЛИіЫїв§жЛАќКЌЕЅИіСаЃЌвЛИіБэПЩвдгаЖрИіЕЅСаЫїв§
Ыїв§НЈСЂГЩФФжжЫїв§РраЭЃП
ИљОнЪ§Онв§ЧцРраЭздЖЏбЁдёЕФЫїв§РраЭ
Г§ПЊ innodb в§ЧцжїМќФЌШЯЮЊОлДиЫїв§ ЭтЁЃ innodb ЕФЫїв§ЖМВЩгУЕФ B+TREE
myisam дђЖМВЩгУЕФ B-TREEЫїв§
// ЫцБэвЛЦ№НЈЫїв§ЃК
CREATE TABLE customer (id INT(10) UNSIGNED AUTO_INCREMENT ,customer_no VARCHAR(200),customer_name VARCHAR(200),
PRIMARY KEY(id),
KEY (customer_name)
);
зЂвтЃКЫцБэвЛЦ№НЈСЂЕФЫїв§ Ыїв§УћЭЌ СаУћ(customer_name)
// ЕЅЖРНЈЕЅжЕЫїв§ЃК
CREATE INDEX idx_customer_name ON customer(customer_name);
// ЩОГ§Ыїв§ЃК
DROP INDEX idx_customer_name ;
3ЁЂЮЈвЛЫїв§
Ыїв§СаЕФжЕБиаыЮЈвЛЃЌЕЋдЪаэгаПежЕ
// ЫцБэвЛЦ№НЈЫїв§ЃК
CREATE TABLE customer (id INT(10) UNSIGNED AUTO_INCREMENT ,customer_no VARCHAR(200),customer_name VARCHAR(200),
PRIMARY KEY(id),
KEY (customer_name),
UNIQUE (customer_no)
);
зЂвтЃКНЈСЂЮЈвЛЫїв§ЪББиаыБЃжЄЫљгаЕФжЕЪЧЮЈвЛЕФЃЈГ§СЫnullЃЉЃЌШєгажиИДЪ§ОнЃЌЛсБЈДэЁЃ
// ЕЅЖРНЈЮЈвЛЫїв§ЃК
CREATE UNIQUE INDEX id x_customer_no ON customer(customer_no);
// ЩОГ§Ыїв§ЃК
DROP INDEX idx_customer_no on customer ;
4ЁЂИДКЯЫїв§
МДвЛИіЫїв§АќКЌЖрИіСа
дкЪ§ОнПтВйзїЦкМфЃЌИДКЯЫїв§БШЕЅжЕЫїв§ЫљашвЊЕФПЊЯњИќаЁ(ЖдгкЯрЭЌЕФЖрИіСаНЈЫїв§)
ЕББэЕФааЪ§дЖДѓгкЫїв§СаЕФЪ§ФПЪБПЩвдЪЙгУИДКЯЫїв§
// ЫцБэвЛЦ№НЈЫїв§ЃК
CREATE TABLE customer (id INT(10) UNSIGNED AUTO_INCREMENT ,customer_no VARCHAR(200),customer_name VARCHAR(200),
PRIMARY KEY(id),
KEY (customer_name),
UNIQUE (customer_name),
KEY (customer_no,customer_name)
);
// ЕЅЖРНЈЫїв§ЃК
CREATE INDEX idx_no_name ON customer(customer_no,customer_name);
// ЩОГ§ Ыїв§ЃК
DROP INDEX idx_no_name on customer ;
5ЁЂЛљБОгяЗЈ
// ДДНЈ
ALTER mytable ADD [UNIQUE ] INDEX [indexName] ON (columnname(length))
// ЩОГ§
DROP INDEX [indexName] ON mytable;
// ВщПД
SHOW INDEX FROM table_name\G
// ЪЙгУALTERУќСюгаЫФжжЗНЪНРДЬэМгЪ§ОнБэЕФЫїв§ЃК
ALTER TABLE tbl_name ADD PRIMARY KEY (column_list): ИУгяОфЬэМгвЛИіжїМќЃЌетвтЮЖзХЫїв§жЕБиаыЪЧЮЈвЛЕФЃЌЧвВЛФмЮЊNULLЁЃ
ALTER TABLE tbl_name ADD UNIQUE index_name (column_list): етЬѕгяОфДДНЈЫїв§ЕФжЕБиаыЪЧЮЈвЛЕФЃЈГ§СЫNULLЭтЃЌNULLПЩФмЛсГіЯжЖрДЮЃЉЁЃ
ALTER TABLE tbl_name ADD INDEX index_name (column_list): ЬэМгЦеЭЈЫїв§ЃЌЫїв§жЕПЩГіЯжЖрДЮЁЃ
ALTER TABLE tbl_name ADD FULLTEXT index_name (column_list):ИУгяОфжИЖЈСЫЫїв§ЮЊ FULLTEXT ЃЌгУгкШЋЮФЫїв§ЁЃ
6ЁЂИЈжњЫїв§
ИЈжњЫїв§:ВщбЏЪ§ОнЕФЪБКђВЛПЩФмЖМЪЧгУidзїЮЊЩИбЁЬѕМўЃЌвВПЩФмЛсгУnameЃЌpasswordЕШзжЖЮаХЯЂЃЌФЧУДетИіЪБКђОЭЮоЗЈРћгУЕНОлМЏЫїв§ЃЈжїМќЫїв§ЃЉЕФМгЫйВщбЏаЇЙћЁЃОЭашвЊИјЦфЫћзжЖЮНЈСЂЫїв§ЃЌетаЉЫїв§ОЭНаИЈжњЫїв§ЃЈЕЅжЕЫїв§ЁЂЮЈвЛЫїв§ЁЂИДКЯЫїв§ЃЉ
ЬиЕуЃКИЈжњЫїв§ЕФвЖзгНсЕуДцЗХЕФЪЧИЈжњЫїв§НЈСЂЕФзжЖЮЫљдкЕФФЧеХБэЕФжїМќЕФОлМЏЫїв§Ъ§ОнПщЕФЕижЗЁЃ
ВщевСїГЬЃКЕБЭЈЙ§ИЈжњЫїв§ВщевЪБЃЌЯШЭЈЙ§ИЈжњЫїв§ЃЌЛёШЁОлМЏЫїв§ЃЌдйЭЈЙ§ОлМЏЫїв§ВщевЕНЯргІЕФЪ§ОнЁЃ
ИЈжњЫїв§гжЗжЮЊИВИЧЫїв§КЭЗЧИВИЧЫїв§ЃК
- ИВИЧЫїв§
ЯТУцгяОфНаИВИЧЫїв§:жЛдкИЈжњЫїв§ЕФвЖзгНкЕужаОЭвбОевЕНСЫЫљгаЮвУЧЯывЊЕФЪ§Он
select name from user where name='jason';
- ЗЧИВИЧЫїв§
ЯТУцгяОфНаЗЧИВИЧЫїв§,ЫфШЛВщбЏЕФЪБКђУќжаСЫЫїв§зжЖЮnameЃЌЕЋЪЧвЊВщЕФЪЧageзжЖЮЃЌЫљвдЛЙашвЊРћгУОлМЏЫїв§ШЅВщевЃЁ
select age from user where name='jason';
ЫФЁЂДДНЈЫїв§ЕФддђ
1ЁЂФФаЉЧщПіашвЊДДНЈЫїв§
1. жїМќздЖЏНЈСЂЮЈвЛЫїв§
2. ЦЕЗБзїЮЊВщбЏЬѕМўЕФзжЖЮгІИУДДНЈЫїв§(where КѓУцЕФгяОф)
3. ВщбЏжагыЦфЫќБэЙиСЊЕФзжЖЮЃЌЭтМќЙиЯЕНЈСЂЫїв§
AБэЙиСЊBБэЃКA join B,on КѓУцЕФСЌНгЬѕМў МШ A БэВщбЏ B БэЕФЬѕМўЁЃЫљвд B БэБЛЙиСЊЕФзжЖЮНЈСЂЫїв§ФмДѓДѓЬсИпВщбЏаЇТЪ
вђЮЊдк join жаЃЌjoin зѓБпЕФБэЛсгУУПвЛИізжЖЮШЅБщРњ B БэЕФЫљгаЕФЙиСЊЪ§ОнЃЌЯрЕБгквЛИіВщбЏВйзї
4. ЕЅМќ/зщКЯЫїв§ЕФбЁдёЮЪЬтЃЌwhoЃП(дкИпВЂЗЂЯТЧуЯђДДНЈзщКЯЫїв§)
5. ВщбЏжаХХађЕФзжЖЮЃЌХХађзжЖЮШєЭЈЙ§Ыїв§ШЅЗУЮЪНЋДѓДѓЬсИпХХађЫйЖШ
group by КЭ order by КѓУцЕФзжЖЮгаЫїв§ДѓДѓЬсИпаЇТЪ
6. ВщбЏжаЭГМЦЛђепЗжзщзжЖЮ
2ЁЂФФаЉЧщПіВЛвЊДДНЈЫїв§
1. БэМЧТМЬЋЩй
2. ОГЃдіЩОИФЕФБэ
Why:ЬсИпСЫВщбЏЫйЖШЃЌЭЌЪБШДЛсНЕЕЭИќаТБэЕФЫйЖШ
ШчЖдБэНјааINSERTЁЂUPDATEКЭDELETEЁЃ вђЮЊИќаТБэЪБЃЌMySQLВЛНівЊБЃДцЪ§ОнЃЌЛЙвЊБЃДцвЛЯТЫїв§ЮФМў
3. WhereЬѕМўРягУВЛЕНЕФзжЖЮВЛДДНЈЫїв§
4. Ъ§ОнжиИДЧвЗжВМЦНОљЕФБэзжЖЮЃЌвђДЫгІИУжЛЮЊзюОГЃВщбЏКЭзюОГЃХХађЕФЪ§ОнСаНЈСЂЫїв§ЁЃ зЂвтЃЌШчЙћФГИіЪ§ОнСаАќКЌаэЖржиИДЕФФкШнЃЌЮЊЫќНЈСЂЫїв§ОЭУЛгаЬЋДѓЕФЪЕМЪаЇЙћЁЃ
жЧФмЭЦМі

linuxЯТДюНЈnginxМАХфжУ
ЮФеТФПТМ ЯТдиnginx НтбЙnginxзЪдДАќ зМБИБрвыЛЗОГ АВзАБрвы ВщевАВзАТЗОЖВЂЦєЖЏnginx фЏРРЦїЗУЮЪ ЯТдиnginx ЯТдиЕижЗЃКhttps://nginx.org/en/download.html етРягУЕФЪЧnginx-1.16.1АцБО НтбЙnginxзЪдДАќ зМБИБрвыЛЗОГ АВзАБрвы ВщевАВзАТЗОЖВЂЦєЖЏnginx фЏРРЦїЗУЮЪ http://IP...

ЬкбЖдЦ+tipaskПьЫйДюНЈЛљгкlaravelЕФCMSЭјеО
вЛЁЂЙКТђЬкбЖдЦЗўЮёЦїЃЌЗўЮёЪаГЁ->ЛљДЁЛЗОГ->бЁдёWordPressЦНЬЈОЕЯё ЖўЁЂАДееtipaskНЬГЬАВзА tipaskЙйЗННЬГЬЕижЗhttps://wenda.tipask.com/article/22 ЙйЗННЬГЬЖдаТЪжВЛЬЋгбКУЃЌЮвећРэШчЯТЃК 1.ftpЩЯДЋЮФМў дЦЗўЮёЦїОЕЯёзАдиЭъБЯКѓЃЌфЏРРЦїЗУЮЪЗўЮёЦїЙЋЭјipЃЌЕуЛїЛёШЁШЈЯоКѓЛсЯТдиЗўЮёЦїЯрЙиЕФЮФМў фЏРРЦїЗУЮЪhost urlЃЌИљОнЫљИјЕФ...

ElasticSearchШыУХНЬГЬ
ЪВУДЪЧElasticSearch ЛљгкApache LuceneЙЙНЈЕФПЊдДЫбЫїв§Чц ВЩгУJavaБраД,ЬсЙЉМђЕЅвзгУЕФRESTFul API ЧсЫЩЕФКсЯђРЉеЙЃЌПЩжЇГжBPМЖЕФНсЙЙЛЏКЭЗЧНсЙЙЛЏЕФЪ§ОнДІРэ ПЩгІгУГЁОА КЃСПЪ§ОнЗжЮів§Чц еОФкЫбЫїв§Чц Ъ§ОнВжПт вЛЯпЙЋЫОЪЕМЪгІгУГЁОА гЂЙњЮРБЈ - ЪЕЪБЗжЮіЙЋжкЖдЮФеТЕФЛигІ ЮЌЛљАйПЦЁЂGitHub-еОФкЪЕЪБЫбЫї АйЖШ - ЪЕЪБШежОМрПиЦНЬЈ АВзА Windows...

аЁГЬађУїУївбОЗжАќСЫЃЌЮЊЩЖУЛгаДѓаЁУЛгаБфЃПЃПЃП
ЮЊЪВУДвЊЗжАќ ецЛњдЄРРЪБГіЯжДѓгк2MЃЌЮоЗЈдЄРРЁЃ ЖдЯюФПНјааЙцећЛЎЗж ШчКЮЗжАќ ЪЕМЪВйзї ЯШНЋашвЊЗжАќЕФЮФМўПНБДЕНаЁГЬађИљФПТМЯТ дкapp.jsonжаХфжУЗжАќНсЙЙ(ШчЭМ) аоИФБЛЗжАќжаЕФв§гУТЗОЖЃЌШчЭМЦЌзЪдДЁЂЕМКНURL ПЩвдЩшжУЗжАќЕФдкФФИівГУцМгди ЭМжаБэЪОдкНјШыloginвГУцНјааЯТдиЩшжУЕФЗжАќЃЌallБэЪОдкЫљгаЭјТчЯТЁЃ ЪЇАмНтОіЃЁЗжАќСЫЮЊЩЖЛЙЪЧЬсЪОДѓаЁГЌЙ§2M ЗжАќЕФЮФМўФкЫљв§гУЕФЭтВПЮФМўвВБиаы...

js pixiПђМм МЋЦфЯъЯИЕНЮЛ(ШыУХ)-----зЊди
pixiЪЧвЛИіjs ЕФЧсСПМЖЕФгЮЯЗРрПтПђМмЃЌКмЪЪгУгкзіH5ЕФвЛаЉcanvasЖЏЛЬиаЇЁЃ етЦЊЮФеТЪЧЙигкpixiЕФШыУХНЬГЬ ЃЌРяУцЕФНВНтЗЧГЃЕФЕНЮЛЯИжТЃЌЪЧЮвПДЕНЙ§ЕФЮФеТРяНВНтЕФЫуЪЧзюКУЕФСЫЁЃ ШЅФъПьЙ§ФъПДЕФНЬГЬ ЃЌНёЬьдйЯыПДЕФЪБКђЗЂЯжУЛевЕНЃЌВЛЙ§ОЙ§ВЛаИЕФЫбЫїЛЙЪЧевЕН ЃЌФЧОЭИЯНєИјзЊЙ§РДАЩЁЃ pixi(ШыУХ) PixiНЬГЬ ЛљгкЙйЗННЬГЬЗвыЃЛЫЎЦНгаЯоЃЌШчгаДэЮѓЛЖгЬсPRЃЌзЊ...
ВТФуЯВЛЖ
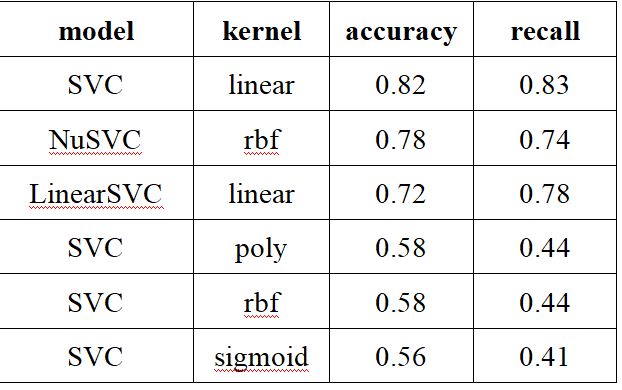
sklearnжЇГжЯђСПЛњЃЈSVMЃЉЖрЗжРрЮЪЬт
ФЃаЭ sklearn.svmжаЕФжЇГжЯђСПЛњЃК ClassifyЃКSVCЁЂnuSVCЁЂLinearSVC RegressionЃКSVRЁЂnuSVRЁЂLinearSVR OneClassSVM БОЮФВЩгУClassifyЯЕСаЃЌclassifyШ§ИіФЃаЭЕФЧјБ№ЃЛВЮЪ§ЯъНт дЄДІРэ НЈФЃ бЕСЗ ЖржжSVCЁЂКЫКЏЪ§ЖдБШ ЖдБШЕФНсЙћЃК гХЛЏlinearКЫКЏЪ§ЕФSVCЕФГЭЗЃЯЕЪ§ ГЭЗЃЯЕЪ§ЃЈC=ЃЉдНИпЃЌЖдДэЮѓЗжРрЕФГЭЗЃ...

ЕквЛНзЖЮЃКCSSГѕВНЬНЬж
ДЋЭГКазгКЭЙжвьКазгЕФГѕНгДЅ зїЮЊвЛИіаЁАзЃЌЕквЛДЮХіЕНетжжКазгЃЌзмЫуФмЖдКазгБфаЮгавЛЕуДжЧГШЯЪЖСЫЃЌВЛЖрЫЕЃЌжБНгЩЯДњТыЙлВь ДЋЭГКазгЕФПэИпЕШгкФкШнЧјгђЕФПэИпЃЌШчЙћpaddingИФБфдђЛсЕМжТећИіКазгБфаЮЃЌГХПЊРДЃЌШчbox1КЭbox1-1ЫљЪО ЙжвьКазгЕФПэИп=ФкШнЕФПэИп+padding2+border2,ЫљвдИФБфpaddingЪБВЛЛсИФБфећИіКазгЕФДѓаЁЃЌВЛЛсБфаЮ...

EtherlabдДТыНтЮі--ecdev_offer()
дкlinuxЯЕЭГжаЃЌЭјПЈМАЖдгІЕФnet_deviceНсЙЙЬхЪЕР§ЪЧгЩЩЯВуЕФЭјТчзгЯЕЭГВйзїЕФЃЌecdev_offer()ЕФзїгУЪЧНЋЭјПЈзЊНЛИјehterlab masterВйзїЁЃ вЛЁЂдЄБИжЊЪЖnet_deviceНсЙЙЬх linuxЯЕЭГжаЃЌУПвЛИіЭјПЈЖдгІвЛИіnet_deviceНсЙЙЬхЕФЪЕР§ЃЌвЛИіЭјПЈвЊФмЙЛБЛФкКЫЪЖБ№ВЂЪеЗЂЪ§ОнЃЌвЛАуашвЊОЙ§net_deviceНсЙЙЬхЕФДДНЈЁЂГѕЪМЛЏЁЂзЂВсЕНФкКЫЁЂДђПЊЩшБИЕШВНжш...

ARMТуЛњЕФжЊЪЖЕузмНс---------10ЁЂНтОіX210ПЊЗЂАхШэПЊЙиАДМќЮЪЬт( в§НХЙІФмИДгУЃЉ
Author: ЯыЮФвевЛЕуЕФГЬађдБ здЖЏЛЏзЈвЕ ЙЄПЦФа дйМсГжвЛЕуЃЌдйздТЩвЛЕу CSDN@ЯыЮФвевЛЕуЕФГЬађдБ РДзджьгаХєЧЖШыЪНЕФбЇЯАБЪМЧ ФПТМ 1ЁЂX210ПЊЗЂАхЕФШэЦєЖЏЕчТЗЯъНт 2ЁЂЮЊЪВУДвЊШэЦєЖЏ 3ЁЂПЊЗЂАхЙЉЕчжУЫјдРэКЭЗжЮі 4ЁЂаДДњТы+ЪЕбщбщжЄ 1ЁЂX210ПЊЗЂАхЕФШэЦєЖЏЕчТЗЯъНт (1)210ЙЉЕчашвЊЕФЕчбЙБШНЯЮШЖЈЃЌЖјЭтВПЪЪХфЦїЕФЪфГіЕчбЙВЛвЛЖЈФЧУДЮШЖЈЃЌвђДЫАхдиСЫвЛИіЮФЮШбЙЦїМўMP1482....

Vue transitionЙ§ЖЩ
Vue transitionЙ§ЖЩ VueдкВхШыЁЂИќаТЛђепвЦГ§DOMЪБЃЌЬсЙЉЖржжВЛЭЌЗНЪНЕФгІгУЙ§ЖЩаЇЙћЁЃ ЃЈ1ЃЉЕЅдЊЫи/зщМўЙ§ЖЩ cssЙ§ЖЩ cssЖЏ...

