


浅谈java中如何实现全文搜索
标签: Java # swing java lucene 搜索引擎
一.什么是全文搜索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程.
那么实现全文搜索的主要2个方向
- 索引的建立
- 索引的查询
如何创建索引,肯定跟业务息息相关. 不同业务数据存在不同的维度, 那么索引创建的关键则是, 如何合理创建索引维度.
二.常见的系统全文搜索软件
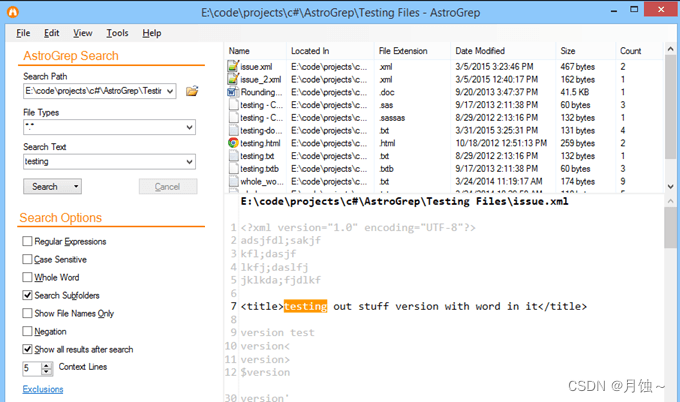
1.AstroGrep
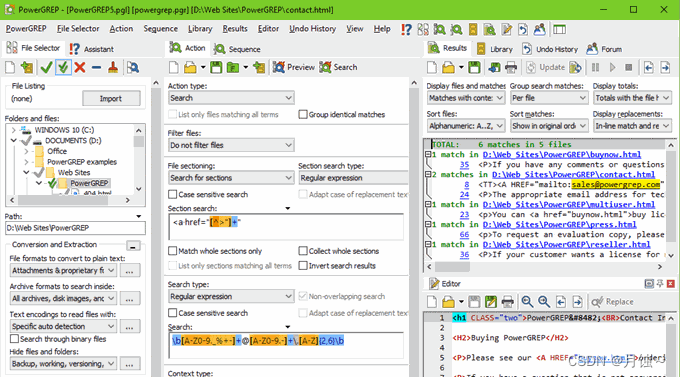
2.PowerGREP
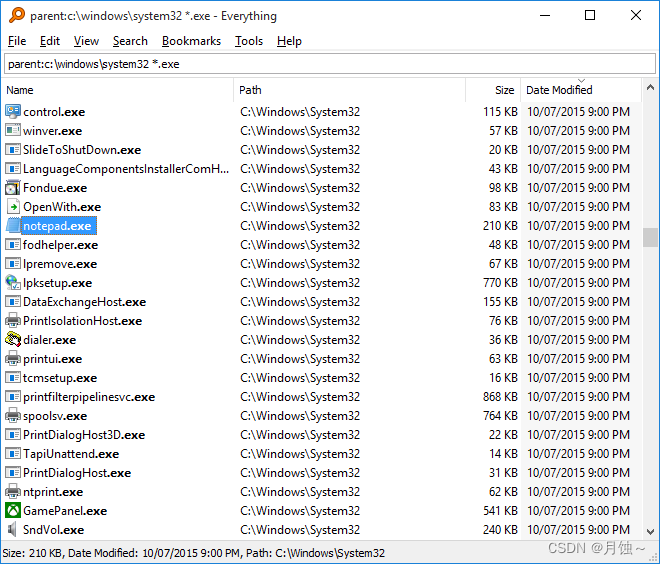
3.Everything等等
三.其他web中常见的全文搜索
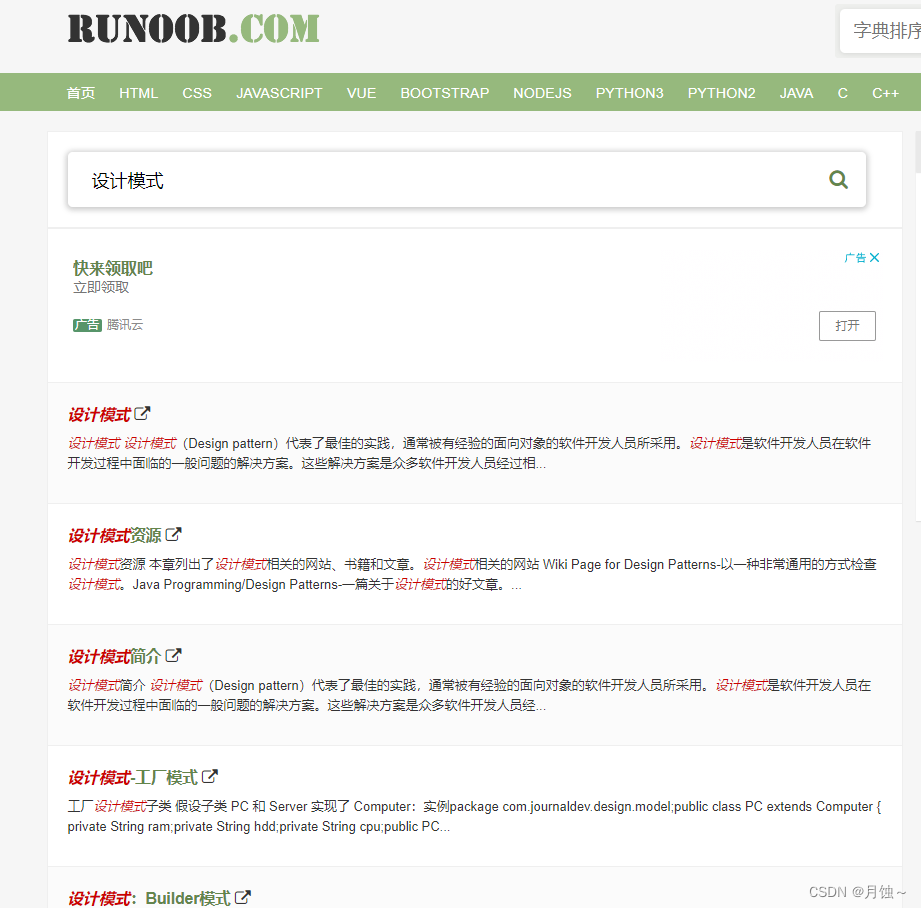
1.百度搜索
2.商城中的商品搜索
3.知识型网站中的文档搜索 等等
四.JAVA中常用的全文搜索框架
内容摘自:https://www.cnblogs.com/hanease/p/15900190.html
1、Java 全文搜索引擎框架 Lucene
毫无疑问,Lucene是目前最受欢迎的Java全文搜索框架,准确地说,它是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene为开发人员提供了相当完整的工具包,可以非常方便地实现强大的全文检索功能。下面有几款搜索引擎框架也是基于Lucene实现的。
官方网站:http://lucene.apache.org/
2、开源Java搜索引擎Nutch
Nutch 是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
利用Nutch,你可以做到以下这些功能:
每个月取几十亿网页
为这些网页维护一个索引
对索引文件进行每秒上千次的搜索
提供高质量的搜索结果
以最小的成本运作
官方网站:http://nutch.apache.org/
3、分布式搜索引擎 ElasticSearch
ElasticSearch就是一款基于Lucene框架的分布式搜索引擎,并且也是一款为数不多的基于JSON进行索引的搜索引擎。ElasticSearch特别适合在云计算平台上使用。
官方网站:http://www.elasticsearch.org/
4、实时分布式搜索引擎 Solandra
Solandra 是一个实时的分布式搜索引擎,基于 Apache Solr 和 Apache Cassandra 构建。
其特性如下:
支持Solr的大多数默认特性 (search, faceting, highlights)
数据复制,分片,缓存及压缩这些都由Cassandra来进行
Multi-master (任意结点都可供读写)
实时性高,写操作完成即可读到
Easily add new SolrCores w/o restart across the cluster 轻松添加及重启结点
官方网站:https://github.com/tjake/Solandra
5、IndexTank
IndexTank是一套基于Java的索引-实时全文搜索引擎实现,IndexTank有以下几个特点:
索引更新实时生效
地理位置搜索
支持多种客户端语言
Ruby, Rails, Python, Java, PHP, .NET & more!
支持灵活的排序与评分控制
支持自动完成
支持面搜索(facet search)
支持匹配高亮
支持海量数据扩展(Scalable from a personal blog to hundreds of millions of documents! )
支持动态数据
官方网站:https://github.com/linkedin/indextank-engine
6、搜索引擎 Compass
Compass是一个强大的,事务的,高性能的对象/搜索引擎映射(OSEM:object/search engine mapping)与一个Java持久层框架.Compass包括:
搜索引擎抽象层(使用Lucene搜索引荐)
OSEM (Object/Search Engine Mapping) 支持
事务管理
类似于Google的简单关键字查询语言
可扩展与模块化的框架
简单的API
官方网站:http://www.compass-project.org/
7、Java全文搜索服务器 Solr
Solr也是基于Java实现的,并且是基于Lucene实现的,Solr的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果。值得注意的是,Solr还提供一款很棒的Web界面来管理索引的数据。
官方网站:http://lucene.apache.org/solr/
8、Lucene图片搜索 LIRE
LIRE是一款基于Java的图片搜索框架,其核心也是基于Lucene的,利用该索引就能够构建一个基于内容的图像检索(content- based image retrieval,CBIR)系统,来搜索相似的图像。
官方网站:http://www.semanticmetadata.NET/lire/
9、全文本搜索引擎 Egothor
Egothor是一个用Java编写的开源而高效的全文本搜索引擎。借助Java的跨平台特性,Egothor能应用于任何环境的应用,既可配置为单独的搜索引擎,又能用于你的应用作为全文检索之用。
五.全文搜索实践
JAVA开发中常用的Eclipse (CTRL+SHIFT+R) 和IDEA(SHIFT+SHIFT) 进行文件搜索时,同样也可以算做一个全文搜索. 如果你也有一个全文搜索的功能需求, 那么怎么实现呢?
1. 索引分析和创建
-
在特定的文件存储目录中 ,建立关于文件的索引信息
遍历该文件夹的所有文件, 创建文件的索引信息 , 可以使用 Files.walkFileTree
-
文件的删除, 重命名,目录变更需要更改索引信息
监听该文件夹,对于文件发生的变更即时更新索引信息 , 可以使用 apache commons-io包的 FileAlterationObserver
FileWatchService
import cn.hutool.log.StaticLog;
import org.apache.commons.io.filefilter.FileFilterUtils;
import org.apache.commons.io.filefilter.IOFileFilter;
import org.apache.commons.io.monitor.FileAlterationListener;
import org.apache.commons.io.monitor.FileAlterationMonitor;
import org.apache.commons.io.monitor.FileAlterationObserver;
import javax.annotation.Nonnull;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* @author jee
* @description: 文件观察服务
* <p>
* + 定义轮询时间 和文件过滤器
* + 指定监听目录
* + 自定义文件监听动作
* <pre>
* // 自定义文件监听事件
* FileWatchAdapter fileWatchAdapter = new FileWatchAdapter(true);
* List<FileAlterationListener> listeners = CollUtil.newArrayList(fileWatchAdapter);
*
* // 创建文件监听
* FileWatchService monitorFile = new FileWatchService.WatchBuilder().dirPath(dirPath)
* .listeners(listeners).build();
*
* monitorFile.start();
*
* // 自定义频率和过滤器
* * FileWatchService monitorFile = new FileWatchService.WatchBuilder(3,FileFilterUtils.suffixFileFilter(".txt")).dirPath(dirPath)
* * .listeners(listeners).build();
*
*
* </pre>
* <p>
* 指定文件过滤监听示例
* <pre>
*
* // txt过滤器
* IOFileFilter filefilter = FileFilterUtils.suffixFileFilter(".txt");
* // 子目录的txt后缀
* IOFileFilter subFilefilter = FileFilterUtils.or(FileFilterUtils.directoryFileFilter(), filefilter);
* //根目录和子目录变化
* IOFileFilter filter = FileFilterUtils.or(filefilter, subFilefilter);
*
* // 创建文件监听
* FileWatchService monitorFile = new FileWatchService.WatchBuilder(5, filter).dirPath(dirPath)
* .listeners(listeners).build();
* monitorFile.start();
*
* </pre>
*/
public class FileWatchService {
/*监听目录*/
private final File fileDir;
/*循环周期*/
private long cycleTime;
/*监听操作*/
private final List<FileAlterationListener> listeners;
/*文件过滤器*/
private final IOFileFilter fileFilter;
/*监听器*/
private final FileAlterationMonitor monitor;
/*监听适配器*/
private final FileAlterationObserver observer;
public FileWatchService(WatchBuilder builder) {
this.fileDir = builder.fileDir;
this.cycleTime = builder.cycleTime;
StaticLog.debug("监听目录: {}, 轮询时间: {}ms", fileDir, cycleTime);
this.listeners = builder.listeners;
this.fileFilter = builder.fileFilter;
observer = new FileAlterationObserver(fileDir, fileFilter);
listeners.forEach(observer::addListener);
monitor = new FileAlterationMonitor(cycleTime, observer);
}
/**
* 启动目录观察器
*
* @throws Exception 实例化observer失败异常
*/
public void start() throws Exception {
StaticLog.debug("启动目录:{} 观察器", fileDir);
monitor.start();
}
/**
* 停止监控
*/
public void destroy() {
try {
if (monitor != null) {
monitor.stop();
StaticLog.debug("停止目录:{} 观察器", fileDir);
}
} catch (Exception e) {
StaticLog.error(e, "文件停止监控失败");
}
}
/**
* @author jee
* @description: builder模式
*/
public static class WatchBuilder {
/*轮询时间*/
private final long cycleTime;
/*文件拦截器*/
private final IOFileFilter fileFilter;
/*文件目录*/
private File fileDir;
/*自定义文件监听器*/
private List<FileAlterationListener> listeners;
/**
* 默认3s轮询一次 ,监听整个目录
*/
public WatchBuilder() {
this(3);
}
/**
* 自定义轮询时间
*
* @param cycleTime 轮询时间
*/
public WatchBuilder(long cycleTime) {
this(cycleTime, FileFilterUtils.trueFileFilter());
}
/**
* 自定义轮询时间和文件过滤器
*
* @param cycleTime 默认轮询时间,单位秒
* @param fileFilter 轮询文件过滤器
*/
public WatchBuilder(long cycleTime, IOFileFilter fileFilter) {
this.cycleTime = TimeUnit.SECONDS.toMillis(cycleTime);
this.fileFilter = fileFilter;
this.listeners = new ArrayList<>();
}
/**
* 设置监听文件目录
*
* @param dirPath 目录绝对路径
* @return WatchBuilder
* @throws IOException 非目录或目录不存在异常!
*/
public WatchBuilder dirPath(String dirPath) throws IOException {
this.fileDir = new File(dirPath);
if (!fileDir.exists()) {
throw new FileNotFoundException("not found: " + fileDir.getAbsolutePath());
}
if (!fileDir.isDirectory()) {
throw new IOException("not a directory: " + fileDir.getAbsolutePath());
}
return this;
}
/**
* 设置监听器
*
* @param listeners 文件监听器集合
* @return WatchBuilder
*/
public WatchBuilder listeners(@Nonnull List<FileAlterationListener> listeners) {
this.listeners.addAll(listeners);
return this;
}
public FileWatchService build() {
return new FileWatchService(this);
}
}
}
2. 建立抽象的文件索引管理器
2.1 实现了索引的初始化 ? 所有文件信息的集合
2.2 实现了索引的自动维护 => 监听文件变化更新索引信息
2.3 未实现的3个方法
应该如何搜索索引?
public abstract List searchIndex(String indexContext);
基本的文件对象, 建立索引时,需要存储哪些东西?
public abstract T fileToIndexObject(File file);
索引信息,怎么反向转换为文件
public abstract File indexToFileObject(T index);
import cn.hutool.core.collection.CollUtil;
import cn.note.service.toolkit.filestore.FileStore;
import cn.note.service.toolkit.filestore.RelativeFileStore;
import cn.note.service.toolkit.filewatch.FileWatchService;
import lombok.Getter;
import lombok.Setter;
import org.apache.commons.io.filefilter.FileFilterUtils;
import org.apache.commons.io.filefilter.IOFileFilter;
import org.apache.commons.io.monitor.FileAlterationListener;
import org.apache.commons.io.monitor.FileAlterationListenerAdaptor;
import java.io.File;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* 文件索引管理器
* 可以用来管理文件基本信息的索引
*
* @param <T> 某种文件性质类型的存储管理器
* @see FileIndexManager
*/
@Getter
@Setter
public abstract class AbstractIndexManager<T> {
/*文件存储对象*/
private FileStore fileStore;
/*文件索引*/
private Map<String, T> indexes;
/*是否初始化完成*/
private boolean initCompleted;
public AbstractIndexManager(String homeDir) {
this(new RelativeFileStore(homeDir));
}
public AbstractIndexManager(FileStore fileStore) {
this.fileStore = fileStore;
this.indexes = new ConcurrentHashMap<>();
}
/**
* 移除文件
*
* @param file 文件
*/
protected void deleteIndex(File file) {
indexes.remove(file.getAbsolutePath());
}
/**
* 添加文件
*
* @param file 文件
*/
protected void addIndex(File file) {
String filePath = file.getAbsolutePath();
indexes.put(filePath, fileToIndexObject(file));
}
/**
* 递归遍历文件和子目录生成索引文件 ,默认所有文件和目录
*/
public void initialize() throws Exception {
initialize(FileFilterUtils.trueFileFilter(), null);
}
/**
* 指定文件过滤器,递归遍历文件和子目录生成索引文件
*
* @param fileFilter 指定文件过滤器
*/
public void initialize(IOFileFilter fileFilter) throws Exception {
initialize(fileFilter, null);
}
/**
* 遍历文件至目录
*
* @param fileFilter 文件过滤器
* @param ignoreDirs 忽略目录
* @throws Exception 遍历文件时发生IO异常, 创建监听器时发生异常
*/
public void initialize(IOFileFilter fileFilter, List<String> ignoreDirs) throws Exception {
AbstractTreeFileVisitor fileVisitor = new AbstractTreeFileVisitor() {
@Override
public void addNode(Path path, boolean isDir) {
File file = path.toFile();
// if (!file.equals(fileStore.homeDir())) {
if (!isDir) {
addIndex(file);
}
}
};
fileVisitor.setFileFilter(fileFilter);
if (ignoreDirs != null) {
fileVisitor.setIgnoreDirs(ignoreDirs);
}
Files.walkFileTree(fileStore.homeDir().toPath(), fileVisitor);
createFileWatch(fileFilter);
}
/**
* 创建文件监听
*/
protected void createFileWatch(IOFileFilter fileFilter) throws Exception {
// 定义拦截动作
FileAlterationListenerAdaptor fileAlterationListenerAdaptor = new FileAlterationListenerAdaptor() {
@Override
public void onFileCreate(final File file) {
addIndex(file);
}
@Override
public void onFileDelete(final File file) {
deleteIndex(file);
}
};
List<FileAlterationListener> listeners = CollUtil.newArrayList(fileAlterationListenerAdaptor);
// 文件过滤器
IOFileFilter subFileFilter = FileFilterUtils.or(FileFilterUtils.directoryFileFilter(), fileFilter);
//根目录和子目录变化
IOFileFilter filter = FileFilterUtils.or(fileFilter, subFileFilter);
// 创建文件监听
FileWatchService monitorFile = new FileWatchService.WatchBuilder(3, filter).dirPath(fileStore.homeDir().getAbsolutePath())
.listeners(listeners).build();
monitorFile.start();
this.initCompleted = true;
}
/**
* @param indexContext 索引内容
* @return 索引集合
*/
public abstract List<T> searchIndex(String indexContext);
/**
* 将文件转文件索引信息
*
* @param file 文件
* @return 文件索引信息
*/
public abstract T fileToIndexObject(File file);
/**
* 索引对象反向转文件对象
*
* @param index 索引对象
* @return 文件对象
*/
public abstract File indexToFileObject(T index);
}
3. 文件基本信息的索引
3.1 包含文件名称,路径,时间, 是否目录等信息
/**
* 文件基本信息类
*/
@Setter
@Getter
public class FileIndex {
/* 文件名称*/
private String fileName;
/* 文件路径*/
private String relativePath;
/* 修改时间 */
private String modifiedDate;
/*是否目录*/
private boolean dir;
/**
* 对fileName 进行忽略大小写
*/
private String searchName;
@Override
public String toString() {
String fmt = StrUtil.format("{}( {})", fileName, relativePath);
return fmt;
}
}
3.2 扩展文件索引管理, 实现文件名称不区分大小写搜索
import cn.hutool.core.util.StrUtil;
import cn.note.service.toolkit.filestore.FileStore;
import java.io.File;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
/**
* @description: 目录索引管理器
* @author: jee
*/
public class FileIndexManager extends AbstractIndexManager<FileIndex> {
public FileIndexManager(String homeDir) {
super(homeDir);
}
public FileIndexManager(FileStore fileStore) {
super(fileStore);
}
@Override
public List<FileIndex> searchIndex(String indexContext) {
if (!isInitCompleted()) {
throw new IllegalStateException("调用是否isInitCompleted 检查初始化是否完成!!!");
}
if (StrUtil.isBlank(indexContext)) {
return Collections.emptyList();
}
final String matchName = indexContext.toLowerCase();
return getIndexes().values().stream().filter(index -> !index.isDir() && index.getSearchName().contains(matchName)).collect(Collectors.toList());
}
@Override
protected FileIndex fileToIndexObject(File file) {
String fileName = file.getName();
String relativePath = getFileStore().getRelativePath(file);
String modifiedDate = getFileStore().getModifiedDate(file);
FileIndex fileIndex = new FileIndex();
fileIndex.setFileName(fileName);
fileIndex.setRelativePath(relativePath);
fileIndex.setModifiedDate(modifiedDate);
fileIndex.setDir(file.isDirectory());
fileIndex.setSearchName(fileName.toLowerCase());
return fileIndex;
}
@Override
public File indexToFileObject(FileIndex index) {
return getFileStore().getFile(index.getRelativePath());
}
}
4. 测试
/**
* 目录文件扫描测试
*/
public class FileIndexManagerTest {
public static void main(String[] args) throws Exception {
String home = SystemUtil.getUserInfo().getCurrentDir() + "/note-service-toolkit";
FileIndexManager fileIndexManager = new FileIndexManager(home);
fileIndexManager.initialize(FileFilterUtils.suffixFileFilter(".java"), CollUtil.newArrayList("target"));
CmdWindow.show((cmd) -> {
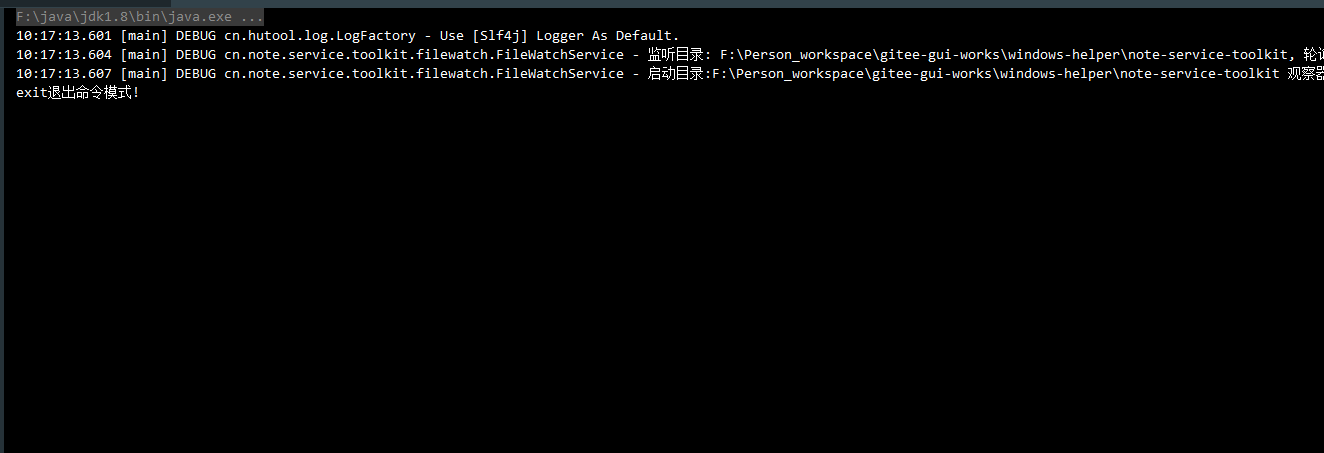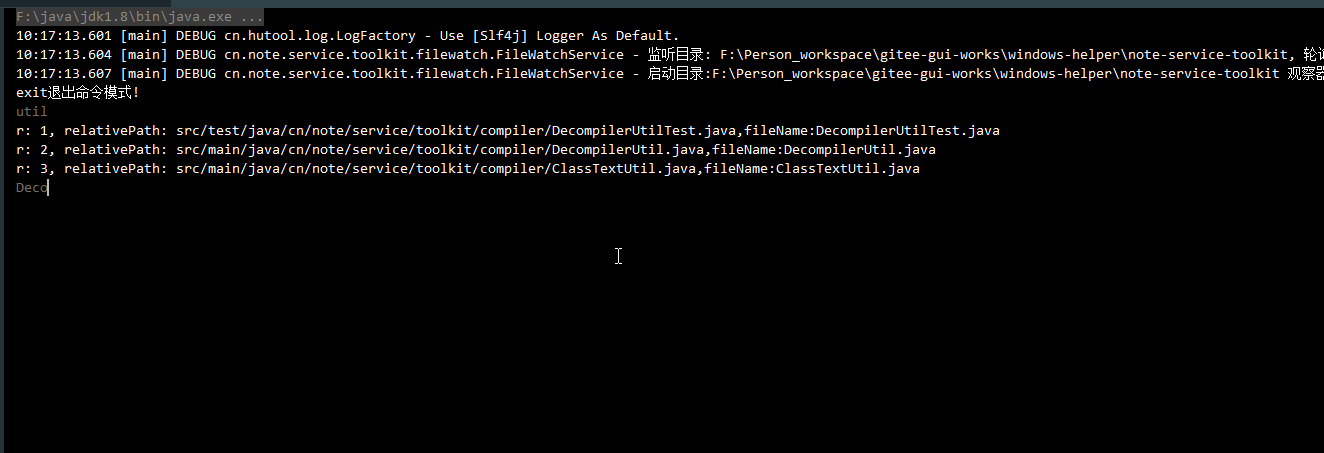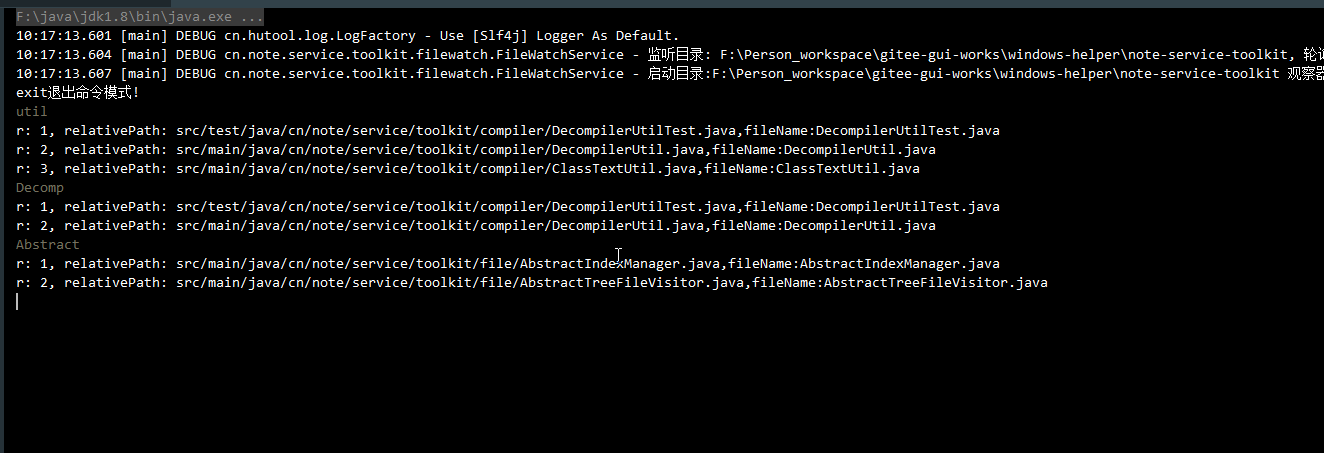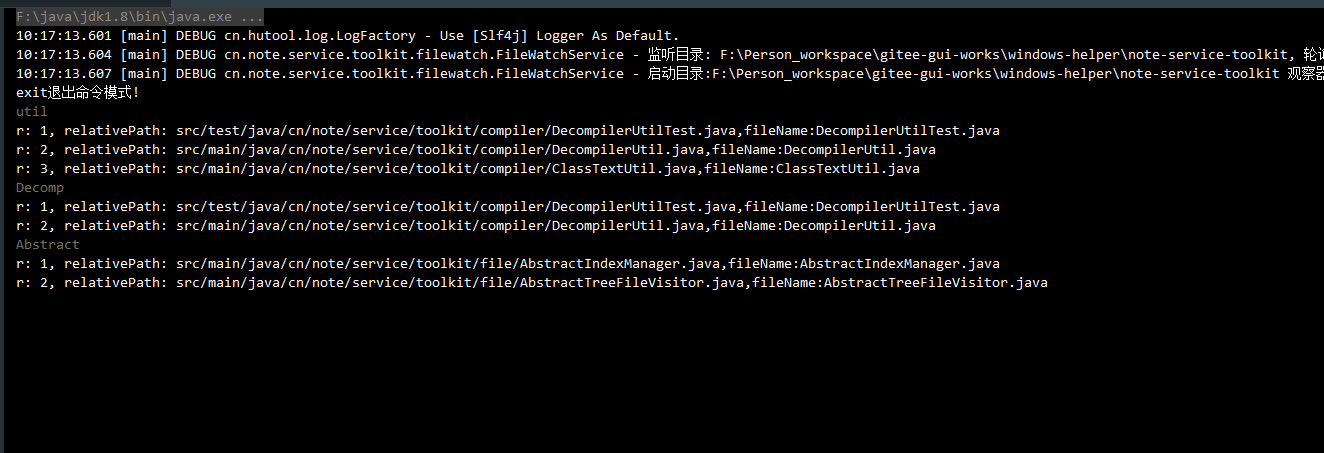
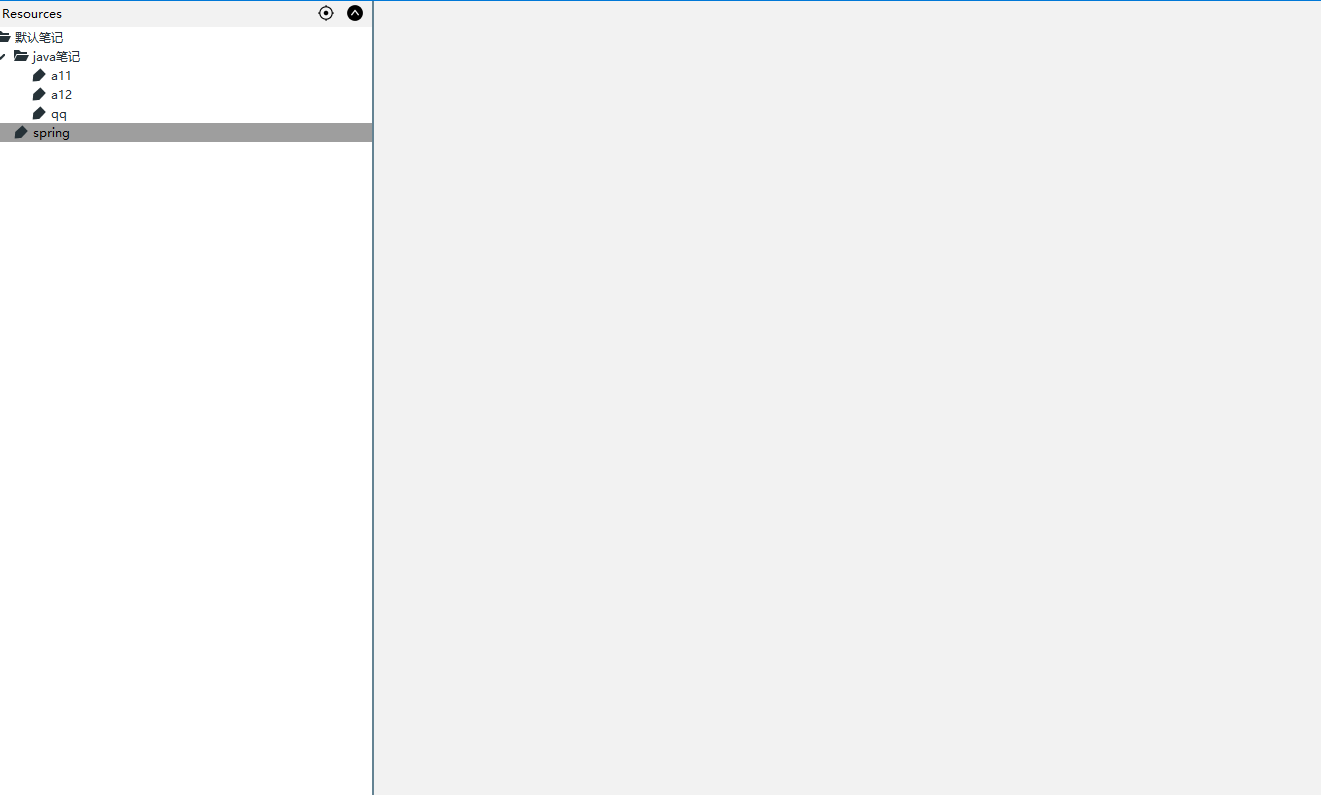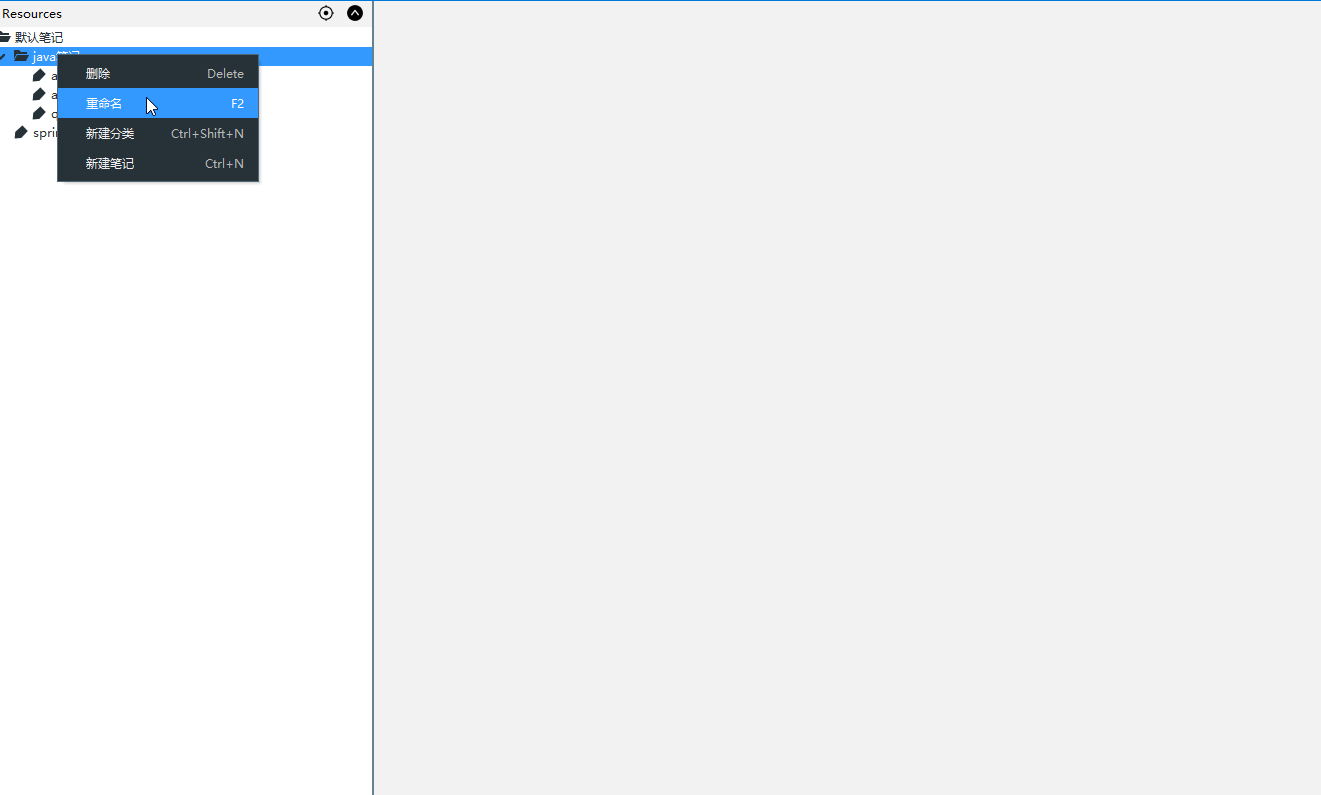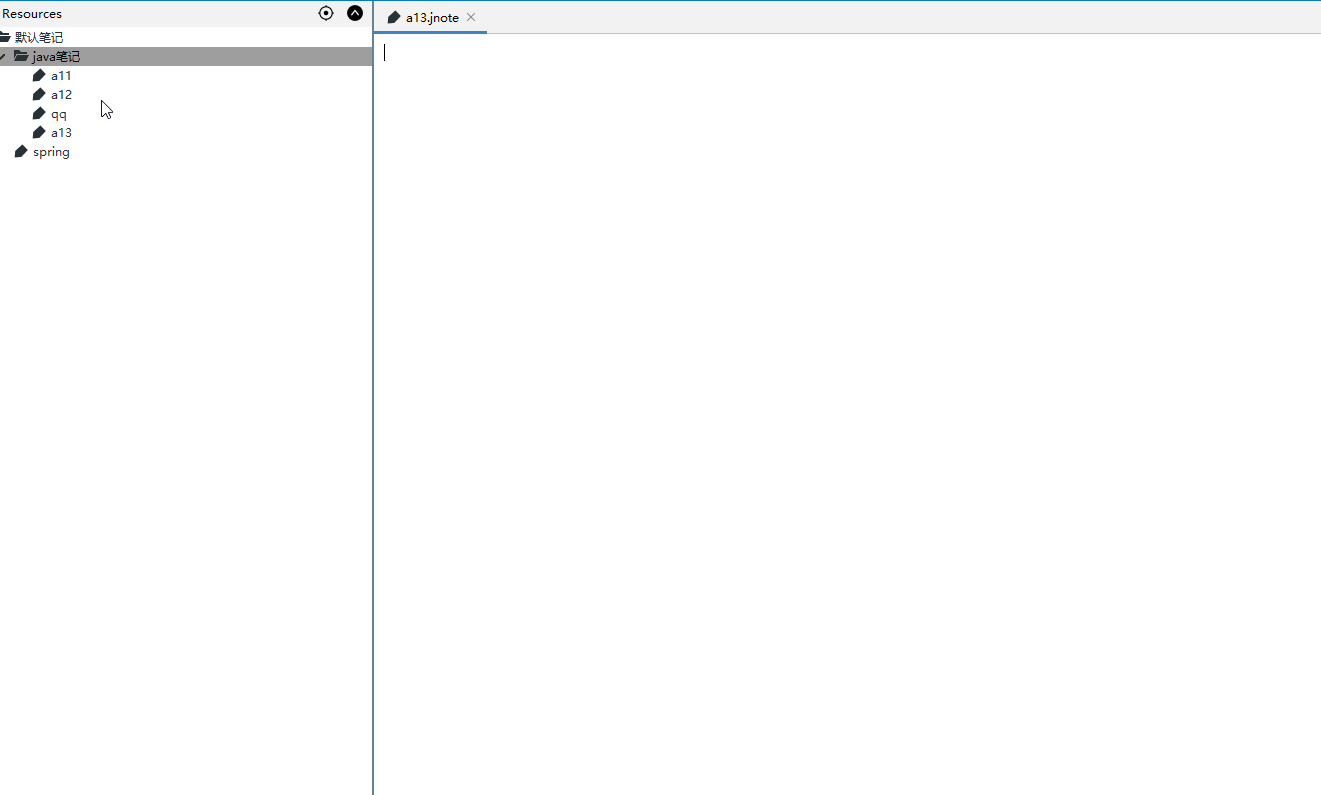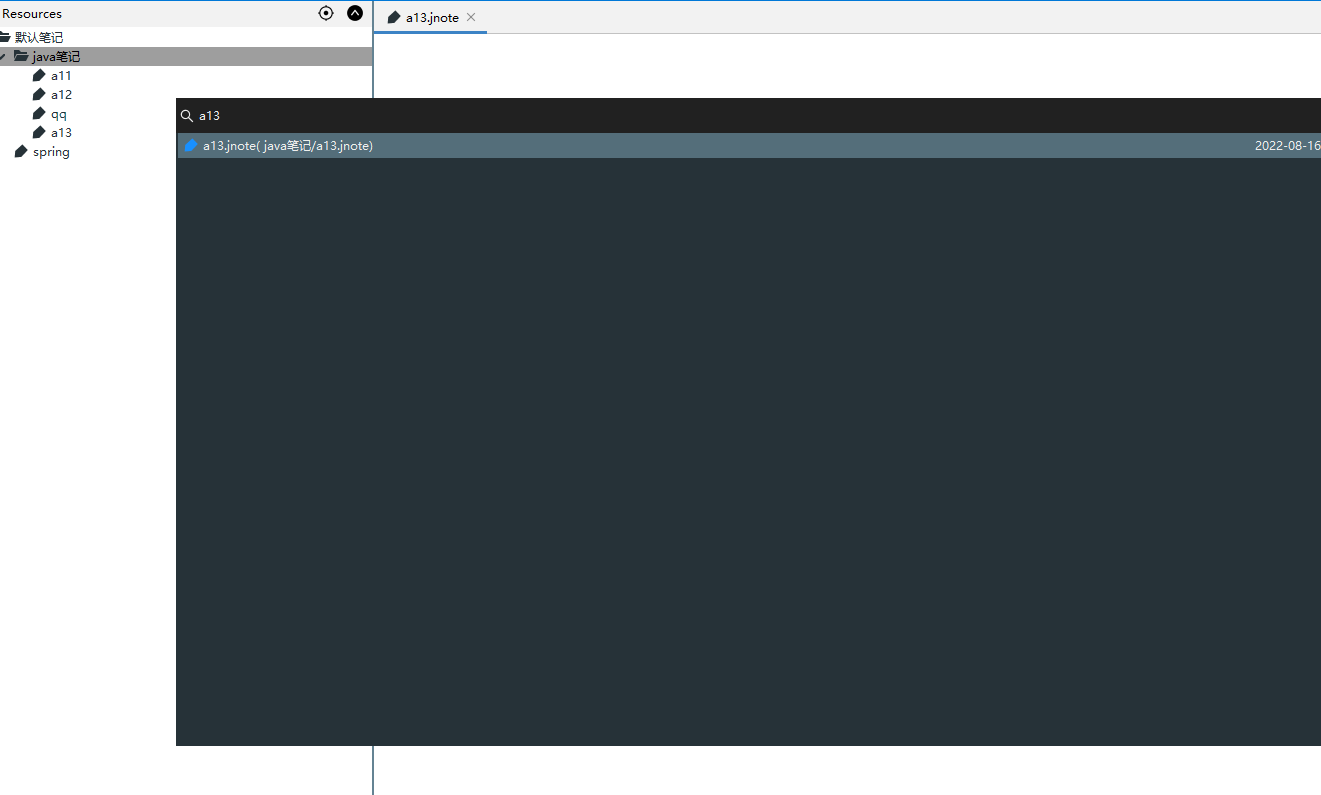
List<FileIndex> noteFileIndices = fileIndexManager.searchIndex(cmd);
if (noteFileIndices.size() == 0) {
Console.log("未匹配到结果!");
}
int i = 1;
for (FileIndex fileIndex : noteFileIndices) {
Console.log("r: {}, relativePath: {},fileName:{}", i, fileIndex.getRelativePath(), fileIndex.getFileName());
i++;
}
});
}
}
5. so… 如何在swing中使用实现一个文件搜索
智能推荐


新发的日常小实验——使用IETester测试不同IE版本的浏览器,测试网页JS的兼容性(console未定义兼容测试)
文章目录 一、痛点:IE兼容测试 二、关于IETester 三、IETester下载 四、写个html测试js的console接口 五、测试结果 六、js兼容处理 一、痛点:IE兼容测试 之前使用.Net的Winform桌面应用框架做了一个PC版的迷你浏览器(使用IE内核),方便拉起网页支付。 有用户反馈打开支付页面报了如下的错:“console”未定义 到底是多么老旧的I...

linux下搭建nginx及配置
文章目录 下载nginx 解压nginx资源包 准备编译环境 安装编译 查找安装路径并启动nginx 浏览器访问 下载nginx 下载地址:https://nginx.org/en/download.html 这里用的是nginx-1.16.1版本 解压nginx资源包 准备编译环境 安装编译 查找安装路径并启动nginx 浏览器访问 http://IP...

腾讯云+tipask快速搭建基于laravel的CMS网站
一、购买腾讯云服务器,服务市场->基础环境->选择WordPress平台镜像 二、按照tipask教程安装 tipask官方教程地址https://wenda.tipask.com/article/22 官方教程对新手不太友好,我整理如下: 1.ftp上传文件 云服务器镜像装载完毕后,浏览器访问服务器公网ip,点击获取权限后会下载服务器相关的文件 浏览器访问host url,根据所给的...

ElasticSearch入门教程
什么是ElasticSearch 基于Apache Lucene构建的开源搜索引擎 采用Java编写,提供简单易用的RESTFul API 轻松的横向扩展,可支持BP级的结构化和非结构化的数据处理 可应用场景 海量数据分析引擎 站内搜索引擎 数据仓库 一线公司实际应用场景 英国卫报 - 实时分析公众对文章的回应 维基百科、GitHub-站内实时搜索 百度 - 实时日志监控平台 安装 Windows...
猜你喜欢

小程序明明已经分包了,为啥没有大小没有变???
为什么要分包 真机预览时出现大于2M,无法预览。 对项目进行规整划分 如何分包 实际操作 先将需要分包的文件拷贝到小程序根目录下 在app.json中配置分包结构(如图) 修改被分包中的引用路径,如图片资源、导航URL 可以设置分包的在哪个页面加载 图中表示在进入login页面进行下载设置的分包,all表示在所有网络下。 失败解决!分包了为啥还是提示大小超过2M 分包的文件内所引用的外部文件也必须...

js pixi框架 极其详细到位(入门)-----转载
pixi是一个js 的轻量级的游戏类库框架,很适用于做H5的一些canvas动画特效。 这篇文章是关于pixi的入门教程 ,里面的讲解非常的到位细致,是我看到过的文章里讲解的算是最好的了。 去年快过年看的教程 ,今天再想看的时候发现没找到,不过经过不懈的搜索还是找到 ,那就赶紧给转过来吧。 pixi(入门) Pixi教程 基于官方教程翻译;水平有限,如有错误欢迎提PR,转...
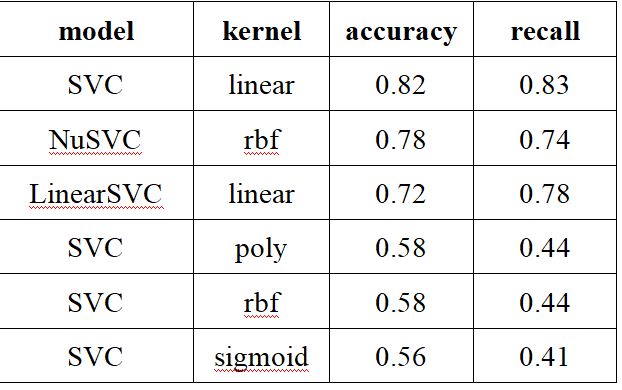
sklearn支持向量机(SVM)多分类问题
模型 sklearn.svm中的支持向量机: Classify:SVC、nuSVC、LinearSVC Regression:SVR、nuSVR、LinearSVR OneClassSVM 本文采用Classify系列,classify三个模型的区别;参数详解 预处理 建模 训练 多种SVC、核函数对比 对比的结果: 优化linear核函数的SVC的惩罚系数 惩罚系数(C=)越高,对错误分类的惩罚...

第一阶段:CSS初步探讨
传统盒子和怪异盒子的初接触 作为一个小白,第一次碰到这种盒子,总算能对盒子变形有一点粗浅认识了,不多说,直接上代码观察 传统盒子的宽高等于内容区域的宽高,如果padding改变则会导致整个盒子变形,撑开来,如box1和box1-1所示 怪异盒子的宽高=内容的宽高+padding2+border2,所以改变padding时不会改变整个盒子的大小,不会变形...

Etherlab源码解析--ecdev_offer()
在linux系统中,网卡及对应的net_device结构体实例是由上层的网络子系统操作的,ecdev_offer()的作用是将网卡转交给ehterlab master操作。 一、预备知识net_device结构体 linux系统中,每一个网卡对应一个net_device结构体的实例,一个网卡要能够被内核识别并收发数据,一般需要经过net_device结构体的创建、初始化、注册到内核、打开设备等步骤...

